
Атрибут rel=canonical позволяет бороться с дублями страниц. Когда одно и то же содержимое доступно по разным URL, канонические ссылки указывают главную страницу. Эта страница (приоритетная) как раз и будет находиться в индексе поисковых систем и весь вес со страниц дубликатов будет перетекать на основную страницу.
Атрибут canonical прописывается на страницах дублей с указанием наиболее приоритетной страницы в разделестраницы вот так:
<link rel="canonical" href="http://site.ru/osnovnoj-url" />
Данный тег прекрасно понимают все основные поисковые системы и канонические ссылки являются для некоторых типов страниц неотъемлемыми с точки зрения SEO оптимизации. Об этом всем мы с вами поговорим сегодня.
Rel canonical: что это
Когда на один и тот же контент можно попасть с помощью разных URL’ов, в индексе поисковых систем начинает участвовать сразу несколько страниц. В итоге ни одна страница толком не продвигается, так как внутренние ссылки идут то на одну страницу, то на другую.
Тоже самое касается внешних ссылок. Невозможно сосредоточиться максимально на продвижении одной страницы, а это в итоге не раскрывает потенциал страницы полностью. Или же, к примеру, покупаются ссылки на одну страницу, а на самом деле в индексе совершенно другая страница.
В результате чего сайт будет занимать позиции ниже, чем мог бы. Атрибут rel=canonical как раз позволяет нам оставить в индексе только самую приоритетную страницу. Также весь ссылочный вес передается на нее.
Чтобы в индексе была только одна страница, нужно прописать на страницах дубликатах в разделеканоническую ссылку на приоритетную:
<link rel="canonical" href="http://site.ru/prioritetnya-stranica" />
Откуда могут появиться дублирующиеся страницы?
Если для удаления дублей, можно воспользоваться 301 редиректом, я рекомендую в первую очередь обратить внимание на него. Если же 301 редирект не помогает или его использование неуместно, то на помощь можно позвать канонические ссылки, только будьте аккуратными.
Статья сайта относится к нескольким рубрикам
Если в ЧПУ вашего сайта выводится рубрика статей, то можно столкнуться с проблемой. Одна и та же статья может располагаться сразу по нескольким URL адресам. Вот у меня, к примеру, есть статья про безопасность в WordPress, она располагается сразу в 2-х категориях: “Полезное для блога” и “WordPress плагины”. Поэтому доступна сразу по 2-ум разным URL адресам:
- https://reclampa.ru/sozdanie-bloga/poleznoe_dlya_bloga/bezopasnost-wordpress.html
- https://reclampa.ru/sozdanie-bloga/razdel-4-plaginy/bezopasnost-wordpress.html
Это для нас, обычных посетителей, как будто страница одна и та же. Для поисковиков же это 2 разные страницы, которые являются дублями. И они могут включить в индекс либо сразу обе страницы, либо не ту, которую хотелось бы. Как раз в подобных случаях выручает rel=canonical, который позволяет указать поисковикам, что нужно проиндексировать только одну конкретную страницу.
В моем случае со страницы https://reclampa.ru/sozdanie-bloga/poleznoe_dlya_bloga/bezopasnost-wordpress.html прописан канонический URL на https://reclampa.ru/sozdanie-bloga/razdel-4-plaginy/bezopasnost-wordpress.html и поэтому в индексе только второй вариант страницы.
Данный rel=canonical у меня прописывается автоматически с помощью плагина для WordPress, более подробно в конце урока.
Товары интернет-магазина в нескольких категориях
Еще одно из самых популярных явлений, это когда товары в интернет-магазинах расположены сразу в нескольких категориях. В виде примера приведу товар iPhone 6s, который может располагаться сразу на нескольких страницах:
- site.ru/apple/iphone6s/
- site.ru/mobilnye-telefony/iphone6s/
- site.ru/catalog/iphone6s/
Все точно также, нужно указать со всех страниц rel=canonical на основную, приоритетную страницу. Как выбрать правильно каноническую страницу расскажу ниже.
Страница печати, разные id
Также на некоторых страницах встречаются страницы для печати. У них к URL добавляется что-то вроде ?print=true. То есть, один и тот же контент может находиться на:
- site.ru/content/post-1;
- site.ru/content/post-1?print=true.
В таком случае со страницы site.ru/content/post-1?print=true нужно прописать в область(внимание, не в body!) следующее:
<link rel="canonical" href="http://site.ru/content/post-1" />
Благодаря этому действию, страница site.ru/content/post-1?print=true не будет участвовать в поиске, то есть не будет проиндексирована.
Также встречаются всякие &id=xxx , с ними боремся точно так же.
Тег more
Еще один популярный тег присваиваются статьям в стиле /#more-777 , который прописывается к URL. Чаще всего такое можно заметить на шаблонах WordPress, особенно старых. Чтобы в индекс попадала правильная страница, аналогично на странице site.ru/post#more-777 должно быть прописано :
<link rel="canonical" href="http://site.ru/post" />
Я же в идеале бы рекомендовал делать ссылки прямыми (с той же самой главной страницы), без тега more.
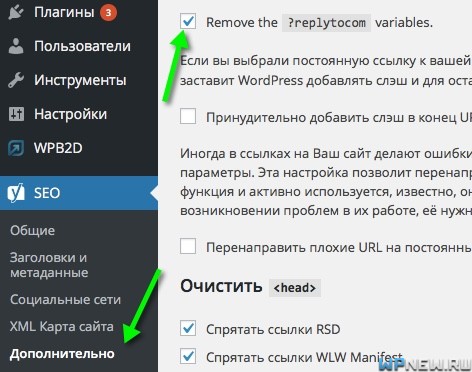
Дубли replytocom
Точно также бывает с ?replytocom=777 , которые могут попасть в индекс из-за древовидных комментариев. Делаем все по аналогии. Я же для борьбы с дублями replytocom просто ставлю галочку в плагине Yoast SEO и данная проблема больше не беспокоит:
Партнерская программа
Когда реализуете партнерскую программу, часто много ссылок c “хвостами” начинают ссылаться на вас. Получается, что-то вроде этого: site.ru/?partner=id777. С подобных страниц тоже нужно прописывать атрибут canonical, чтобы они не попали в индекс.
Как правильно использовать rel=canonical
Как вы уже поняли, чтобы в индексе был только 1 вариант страницы, нужно со всех дублирующихся страниц проставить атрибут canonical. Вот как он должен выглядеть
<link rel="canonical" href="http://site.ru/osnovnoj-url" />
Данный тег должен находиться внутри.
Как правильно выбрать канонический урл?
Каноническая страница – это та страница, которая рекомендуется поисковикам для индексации среди всех дублей. Какую же лучше выбрать?
- Если страница раньше имела только 1 url, то лучше сделать канонической ее, так как скорей всего она уже проиндексирована, также имеет определенный вес. То есть с новой страницы проставить rel=canonical на старую.
- Если же страницы создавались примерно в одно время, лучше каноническим URL сделать ту, которая находится в индексе.
- Если же несколько страниц-дублей находится в индексе поисковиков, то лучше выбрать тот, который будет продвигаться. Чаще всего тот URL, который имеет меньше всего уровень вложенности, либо уже имеет входящие ссылки.
- Если же все условия идентичные у страниц дублей, обычно берется за приоритетную страницу та, которая подходит под некий шаблон товара/статьи по сайту и предпочтение отдается единообразию.
Частые ошибки с атрибутом rel=canonical
- Тег rel=”canonical” – это не строгая директива. Он лишь предлагает основную страницу для поисковиков, то есть просто-напросто советует.
- Нельзя использовать другой домен в данном атрибуте. Допускаются ссылки только внутри домена или поддомены.
- Для проставления канонических ссылок необязательно иметь 100% дублированный контент, если есть небольшие различия – это нормально. Такое может быть, когда продукты расставлены в другом порядке или поисковый робот посетил страницы в разное время, например.
- Если документ по каноническому адресу недоступен (отдает 404 ошибку, допустим), то поисковики могут проигнорировать его.
- Также поисковые роботы могут проигнорировать данный атрибут, если на странице указано несколько канонических урлов.
- Для указания канонического ссылки допускается использовать не полный URL адрес, а относительный путь:
<link rel="canonical" href="/osnovnoj-url" />
Но будьте аккуратны, можете “наломать дров”, лучше использовать полный URL, с указанием вашего домена.
- Каноническая страница должна быть индексируемой.
Запомните: rel=canonical передает вес входящих ссылок.
Почитайте еще эти статьи (официальные руководства от Яндекса и Google):
Частные случаи использования rel=canonical
Сanonical сама на себя
Меня не раз спрашивали, можно ли ставить каноническую ссылку саму на себя? Такое обычно происходит при автоматической генерации с помощью разных плагинов или силами CMS. Ответ – да, можно, ничего в этом плохого нет.
Canonical для страниц пагинации
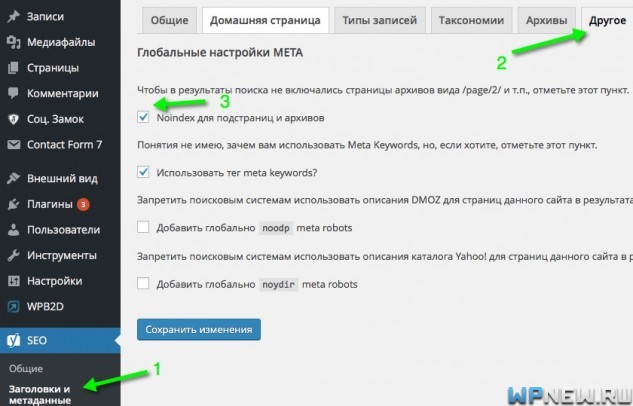
Многие вебмастера хотят сделать rel=canonical со страниц пагинации (site.ru/category/page/2) на первую страницу (site.ru/category). Это неправильно, как я считаю. Все-таки здесь встречаются не полные дубли, такие страницы пагинации лучше закрыть с помощью:
<meta name="robots" content="noindex,follow"/>
В WordPress это можно сделать автоматически, поставив галочку в плагине WordPress SEO by Yoast:
Товары
Если товары разделены на несколько страниц (их много и сделана разбивка на несколько страниц), то лучше основным каноническим урлом сделать вывод всех товаров, которое обычно выводится с помощью добавления к URL что-то подобное этому ?all=products.
Атрибут rel=canonical в WordPress
Многие SEO плагины для WordPress очень хорошо дружат с атрибутом rel=canonical. Мой любимый и, как я считаю, лучший SEO плагин Yoast SEO вообще ничего не требует. Просто достаточно его активировать и необходимые канонические URL сами прописываются.
В некоторых других SEO плагинах в настройках нужно просто поставить галочку напротив “Канонические страницы” (или еще что-то подобное).
То есть по умолчанию, если статья на моем блоге присвоена сразу к нескольким категориям, то автоматически прописывается каноническая страница. Именно поэтому на странице https://reclampa.ru/sozdanie-bloga/poleznoe_dlya_bloga/bezopasnost-wordpress.html у меня прописан следующий атрибут rel=canonical (обратите внимание, это другой URL):

По умолчанию, благодаря плагину Yoast SEO, если пост располагается сразу в нескольких категориях, в индекс же попадает только один вариант.
Выводы
Я надеюсь, что вполне понятно, смог объяснить, что такое атрибут rel=canonical и как им пользоваться. Настоятельно рекомендую ознакомиться вам еще с этим уроком: Как удалить ненужные страницы в индексе Яндекса и Google. Все эти действия с rel=canonical, 301-ым редиректом, meta name robots, файлом robots.txt позволят сделать выдачу вашего сайта “чистым”.
Я за “чистый” индекс без дублей, служебных страниц и пр. ненужных вещей. Благодаря чистоте SEO продвижение сайта будет проще и правильнее.
И еще: чтобы не было подобных заморочек я рекомендую будущие ваши сайты создавать без указания категорий в URL статей/товаров. То есть пусть будет что-то вроде:
- site.ru/statya.html (для блогов);
- site.ru/catalog/iphone6s (для интернет-магазинов).
Отдельное спасибо за ретвиты и репосты, мои друзья. Обязательно жду ваших мыслей в комментариях.




{kind=link}
{kind=link}
Первый нах 🙂
Сейчас , Петр, rel=”canonical” проставляется автоматически в Word press. Если добавить еще его в плагине, получиться двойной “каноникаль”. В этом случае роботы не будут принимать во внимание ни одного. У вас не новые данные, Петр, сейчас здесь есть перемены. Извините за уточнения.
Я немного вас разочарую, это не так. В исходном коде вы где-то видите у меня 2 каноникала? Нет. Выводится только rel=canonical у плагина Yoast SEO. В плагине Yoast SEO все настроено правильно, поэтому нет дублирование. А дублирование, насколько мне известно, встречалось в плагине All is SEO Pack, я же им не пользуюсь, поэтому не знаю про это ничего: может они уже исправили свой этот баг.
Повторюсь, если пользоваться лучшим SEO плагинов WordPress SEO by Yoast никаких проблем с дублированием канонических URL нету. Поэтому, скорей у вас немного устаревшие данные, без обид 😉
Полностью соглашусь на счёт плагина WordPress SEO by Yoast, сам им пользуюсь и проблем с дублями не заметил.
Из опыта большого крупного проекта, по случайности вышел релиз с canonical указывающим на страницы закрытые в robots такая ситуация была неделю, при этом google практический не отреагировал (стал показывать страницы закрытые в robots) а Яндекс стал выбрасывать страницы из поиска….
Мне вот интересно, а если на главной расположено полное содержимое статьи с картинками, ссылками и на второстепенной странице такое же содержимое, то получается дублирующий контент? То есть, это тоже кража “веса”?
Ведь бывает такое, что тег More не используется, даже анонсы должны быть уникальными на главной? И вот миниатюры: везде надо уникальную картинку использовать? внедрять только в записи? Получается, что главную и иже поэтапные, нужно уникальную пилить? С неповторимыми картинками и текстом? Неужели поисковики не могут давать приоритеты? Пётр, прости, может глупый вопрос, но вот такая каша в голове)
Нет, это не дублирующийся контент. Немного не так понял.
Я не использую каноникал, хотя может и пригодиться где. Стараюсь закрыть ненужное в роботсе, а на глюк с пагинацией, установил 301 редирект для первой страницы. Длинные имена урлов тоже не использую, и яндекс и гугл не рекомендуют, дабы не возникало проблем с индексацией (Яндекс: “робот может не понять куда ведет ссылка и что там будет и проигнорирует ее”)
В смысле сделал 301 редирект с пагинацией? То есть вторая и последующая страница недоступна? Тогда это нерпавильно.
Нет, я поставил редирект только со страницы 1 которая была по адресу САЙТ/page/1. Перенаправил ее на главную, ведь страница одна и та же. Как же народ будет информацию искать, если все страницы перенаправить 🙂
Привет!
В консоли гугла конструкция директивы
Disallow: */page/
считается ошибочной, правильнее будет написать Disallow: /*/page/
А чтобы закрыть страницы пагинации нужно разместить meta robots noindex follow
Потому что закрытие через Disallow не спасёт и страницы всё равно будут в индексе – просто с пометкой, что описание закрыто в robots.txt
Для страниц разделов каноникал будет правильнее ставить на страницу, где есть все товары например.
При невозможности создать такую страницу яндекс рекомендует прибегнуть к установке каноникала на первую страницу пагинации, но в гугле такой способ считается ошибочным. Там нужно изворачиваться иначе
Привет. По поводу Disallow, да, про это писал в той статье, на которую давал ссылку в данном уроке https://reclampa.ru/raskrutka-bloga/seo_optimizaciya/kak-udalit-stranicu-iz-indeksa.html Спасибо за подсказку, в этом уроке забыл добавить, сейчас скорректирую.
В консоли гугла конструкция директивы
Disallow: */page/
считается ошибочной
Можешь дать ссылку, не могу найти, что он ругается.
На страницах пагинации правильно указывать rel=canonical с указанием первой страницы как основной. Да контент не полностью дублирован, но он очень похож.
Яндексоиды кстати сами советуют на страницах пагинации использовать каноникал http://platon.ya.ru/replies.xml?item_no=2878
Крутая статейка получилась!
canonical пока никак не использую на своем блоге. Все закрыто через meta name robots, и редиректы через htaccess настроены.
Мне еще повезло, что я никогда не присваиваю одной статье более одной рубрике ))))
Очень нужная статья. WordPress SEO by Yoast и правда лучший плагин!
Спасибо за очередной полезный материал.
Спасибо) пойду подчищу сайты
Недавно на одном SEO форуме как раз обсуждали правильно ли что страница в WordPress ссылается сама на себя в canonical. Теперь буду знать, что ничего страшного в этом нет.
Поздравляю с юбилейным уроком. 🙂 400 однако не хило.
Здравствуй, Петр и читатели этого блога. Я хочу зарабатывать 10-20$ в интернете, можете что-то посоветовать
Очень интересно.
Сразу извиняюсь что комент не по теме статьи ! Петр периодически читаю ваш блог , скажите как вам удалось обогнать блог своего учителя ( Алексея Терехова ) по посещаемости?
А мне SEO by Yoast однажды показался чересчур громоздким. С тех пор и не пользуюсь.
А как насчет rel=”canonical” в страницах, которые переехали с http на https?
Гугл Вебмастер жалуется, что нет карты sitemap на https. Где-то прочитала, что нужно добавить rel=canonical на страницы с HTTPS с рекурсивной ссылкой, создать и сохраните файл Sitemap с HTTP и HTTPS урлами (и в перспективе хранить Sitemap на HTTPS).
Это вобще надо? Я вроде читала твою статью о переезде на https, занесла всё, что было написано в htaccess и robots. Но гугл не видит sitemap.
Есть статейка по этому поводу, как и что делать?
Ещё добавлю к этому вопросу:
После переезда на https компарсер показывает URL и rel=”canonical” не совпадают для всех 100% страниц. Отличие заключается лишь в том, что url доступен по абсолютному протоколу https://, а rel=”canonical” по относительному ://
Все мы знаем, что для поисковых систем это два разных сайта. Зеркала в ЯВебмастер и в Гвебмастер склеены.
Вопрос: на сколько такое несовпадение критично для SEO
Благодарю за ответ.
Не делайте rel=canonical относительный протокол, могут быть проблемы, сделайте абсолютный путь с указанием протокола.
Петр, у меня следующая проблема в этой области – после установки сертификата SSL на хостинге сайт стал доступен по https-протоколу (при этом, редирект с http на https не делали и в админке WP https не прописывали – сайт доступен по обоим протоколам на время склейки).
Однако, при заходе на https в меню часть ссылок по-прежнему содержат адресf на http-версию страниц. Проверили код – оказалось, что на всех страницах, на которые из меню ведут незащищенные ссылки, атрибут rel canonical содержит адрес страницы с незащищенным протоколом. Когда как на страницы, к которым ведут защищенные ссылки этот атрибут содержит защищенный протокол. Хотя все страницы открывали с защищенного протокола.
Посмотрели настройки атрибута в плагине Yoast – одинаково и у тех, и у других страниц (т.е. поле “Канонический URL-адрес” пустое в обоих случаях).
Отсюда вопрос – влияет ли настройка атрибута canonical на отображение ссылок в меню? И если да, то как нам быть с этим атрибутом? Как вы написали выше, относительный протокол прописывать не стоит. Да и, в целом, почему могут быть разные canonical на страницах, если в настройках Yoast и шаблонах страниц различий нет?
Заранее спасибо!
Пётр, какой материал можно почитать на тему абсолютного пути rel=canonical?
подскажите как это сделать?
как в вордпрессе сделать, чтобы на страницах пагинации была каноническая главная?
rel=canonical прописывать вручную на страницах пагинации или же как то можно в роботс текст сделать?
А в Аллен сео пак это как сделать? Яндекс ругается что нет описания на страницах паже1, 2, 3….
А Вы сейчас отключили canonical? Просто тот пример, который Вы приводите с Вашего сайта не содержит canonical
Добрый день, Петр!
А как следует поступить, если Сайт принадлежит системе Мультисайтов на WordPress, и контент дублируется между этими сайтами.
К примеру – есть сайт по растениям: Статья про “Чернобривцы”. часть этой статьи (1-2 абзаца) может быть продублирована на Кулинарном сайте, а ЧАСТЬ статьи про Грузию (из сайта о путешествиях) – внедрено в текст о Чернобривцах.
Как поступать в данном случае? Можно ли указать Каноникал не в Хедере статьи, а в конкретном абзаце (либо задать каноникал для нескольких абзацев)?