
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt. Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с индексацией сайта я не замечаю, robots.txt работает просто великолепно.
Robots.txt для WordPress
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – продвижение сайта в поисковых системах. То есть составление robots.txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес карты сайта sitemap.xml и прописывается главное зеркало сайта (сайт с www или без www).
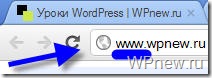
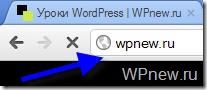
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Было:
Стало (после перехода на сайт, www автоматически удалились, и сайт стал без www):
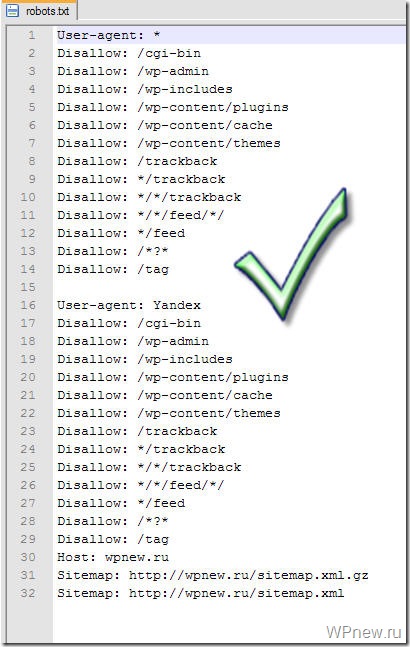
Так вот, этот заветный, по-моему, правильный robots.txt для WordPress Вы можете увидеть ниже.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: reclampa.ru
Sitemap: https://reclampa.ru/sitemap.xml.gz
Sitemap: https://reclampa.ru/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением .txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес reclampa.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://reclampa.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью плагина Google XML Sitemaps.
Возможные проблемы
Если у Вас на блоге не стоит ЧПУ (именно так у меня происходит с тем сайтом, которого я занимаюсь продвижением), то с тем robots.txt, который дан выше, могут быть проблемы. Напомню, что без ЧПУ ссылки на сайте на посты выглядят примерно следующим образом:
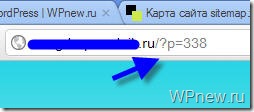
А вот из-за этой строчки в robots.txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: reclampa.ru
Sitemap: https://reclampa.ru/sitemap.xml.gz
Sitemap: https://reclampa.ru/sitemap.xml
Анализ robots.txt
Чтобы проверить, правильно ли мы составили файл robots.txt я рекомендую Вам воспользоваться сервисом Яндекс Вебмастер (как регистрироваться в данном сервисе я рассказывал тут).
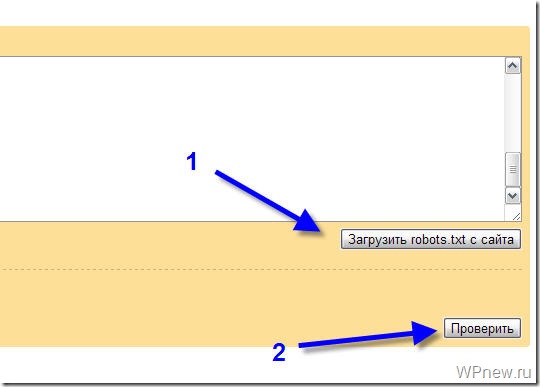
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
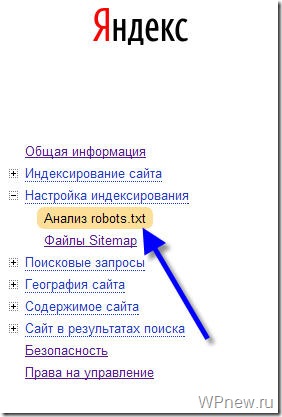
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:
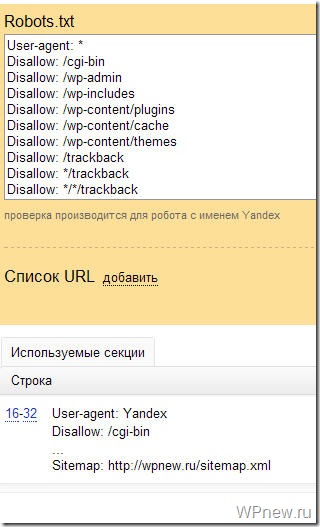
Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:
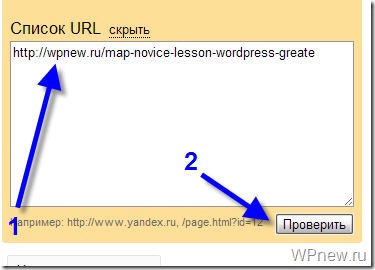
Также Вы можете в “Список URL” добавить адрес любой статьи сайта, чтобы проверить не запрещает ли robots.txt индексирование данной страницы:
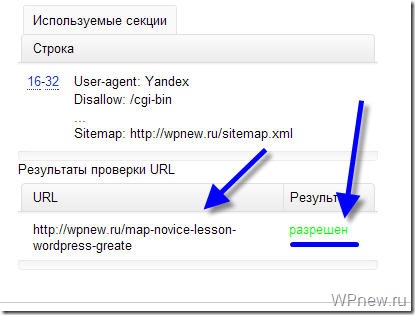
Как видите, никакого запрета на индексирование страницы со стороны robots.txt мы не видим, значит все в порядке :).
Надеюсь больше вопросов, типа: как составить robots.txt или как сделать правильным данный файл у Вас не возникнет. В этом уроке я постарался показать Вам правильный пример robots.txt:
Вы можете посмотреть другие варианты, как еще можно составлять robots.txt.
До скорой встречи!
P.s. Совсем недавно я добавил блог в Яндекс Каталог, что же интересного произошло? 🙂




{kind=link}
{kind=link}
На одном из сайтов проситал, что нужно запретить индексацию Yahoo.
Как Ваше мнение, нужно это сделать или нет?
А зачем собственно говоря это нужно? (как было там написано?), Если честно, я первый раз об этом слышу.
я не совсем разобрался, но, как я понял, Yahoo
практически не дает трафика в рунете, но при этом показывает все ссылки входящие.
Следовательно конкуренты могут видеть какие сайты ссылаются и, следовательно, каким-то образом это использовать 🙂
Ой, я по этому поводу не запариваюсь 🙂 Конкуренты, если нужно, и без Yahoo справятся :).
у меня непонятная проблема с этим файлом..да и не у одного меня
в индексе гугла пару тысяч страниц (сейчас 5080, а было более 7к, при том, что их должно быть около 300)
прикол в чем: переходим сюда
http://www.google.com/search?&q=site:http://sidash.ru
Результатов: примерно 6 140
потом идем на последнюю страницу в поисковике
http://www.google.com/search?&q=site:http://sidash.ru#q=site:http://sidash.ru&hl=ru&prmd=imvns&ei=b8qMTuCECamw0AWys4DpBQ&start=380&sa=N&bav=on.2,or.r_gc.r_pw.r_cp.,cf.osb&fp=703b5ce7af564065&biw=1366&bih=643
и видим
Результатов: 331
я уже и в гугл писал, чтобы сделали перерасчет страниц.. прошло пару недель, а в индексе стало лишь на 1 тысячу страниц меньше
мою проблему никто не знает как решить?
К сожалению, я нет…
Уважаемый sidash!
1 вариант который вы привели – это просто поисковый запрос,
2 вариант более конкретизированный, и показывает только результаты по сайту
Привет Петер 🙂 Тут для меня америка не открылась, но вспомнился вопрос касаемо тех самых дублирующихся статей. Хотелось бы поболее инфы получить именно об этом. Почему такое пишу: у меня на сайте немало вхождений с ПС именно с тегов (то есть ПС выдают страницу какого-либо тега “сайт/tag/название тега”). Сегодня попробую закрыть всё, посмотрю как скажется на посещениях.
По-моему, вы уже об этом писали, Петр!
Я просто давал robots.txt. А здесь постарался разъяснить что к чему.
Еще хотел бы добавить, в некоторых темах на wp, появляются ненужные ссылки. У меня была такая – /?printf=1 (печать записи), яндекс нашел к ней ссылки и проиндексировал – в итоге дублированный контент. Я удалил в теме ссылку, ой так о чем же я говорю, у нас же темы одинаковые. У тебя тоже может быть эта ссылка. В общем, я запретил в роботсе еще и /?print
Спасибо. Проверил свой, кстати нашел в выдаче страницы вида сайт/tag, сейчас добавлю Disallow: /tag. Карта блога стоит только для робота, на самом блоге для посетителей не смог поставить – тема выдает ошибку и белый лист.
Я у себя решил этот вопрос установкой другого плагина, выдаёт такой аккуратненький список всех статей в штмле)
Петр, если версия этого robot.txt чем-то отличается от версии, указанной в этом https://reclampa.ru/sozdanie-bloga/razdel-5-perenos/perenos-bloga-wordpress.html уроке, Вы не могли бы указать отличия?
Не отличается. Единственное – рассказал зачем он нужен, этот файл. И рассказал про нюансы, если вдруг не будет на блоге ЧПУ. Потому что если нет ЧПУ и поставить robots.txt c https://reclampa.ru/sozdanie-bloga/razdel-5-perenos/perenos-bloga-wordpress.html то с вылетят все страницы с индекса, как произошло у меня с продвигаемым сайтом клиента. Благо во время все заметил и быстро исправил данную невнимательность. Страницы в индекс вернулись очень быстро.
хоть не в тему но поздравляю с ТИЦ 40!! Скоро очередная цель будет достигнута!
точно, и PR-ом “0”, как впрочем и у google.com 🙂
так похожий урок был уже
Отлично написано. Без лишнего бла, бла, бла, всё просто, понятно и с примерами!
Привет, Петр! стала твоей постоянной читательницей.
У меня вот гугл наиндексировал кучу ненужного, я добавила в робот
Disallow: /tag
Disallow: /archive
Disallow: /page
Disallow: */comment-page-*
Disallow: *?replytocom
Подскажи, правильно ли это?
Что за Disallow: *?replytocom ? 🙂 Такие страницы в индексе?
Я так поняла, это в комментариях. Гугл написал что страницы запрещены роботом, но он их почему-то все-равно видит, вот в робот и добавила эту строчку.
С файлом robots.txt всё индивидуально, поскольку от вида адреса постов зависит и то, как следует закрывать дублирующие страницы:
Например, может быть так:
Disallow: /tag/
А может и так:
Disallow: /?tag=
Я на новые блоги скопировал роботс с сайта ктонановенького. На старых ничего не меняю. Там все индексируется хорошо.
Спасибо за полезную инструкцию. Все сделала, но при проверке Яндекс выдает всего 3 строки:
User-agent: *
Disallow:
Sitemap: kuspehy.ru/sitemap.xml.gz
Я что-то неправильно сделала? Я куда надо было на Вордпресс загрузить этот файл ?
Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др.
Там и находится!
У меня прописанно
Disallow: /wp-content/plugins
но все равно в гугле индексируется плагин нот капча, вчем дело может быть?
Только этот плагин индексируется?
Петр, Вы не подскажите: Могут ли, из-за неправильного robots.txt, страницы выпасть из индекса яндекса?
Читайте урок внимательней, там же написано, что из-за неправильного robots.txt на несколько дней (потом я исправил эту проблему) у меня выпали из индекса почти все страницы клиента, чей сайт я продвигаю.
Через robots.txt можно запретить поисковикам индексировать даже ВЕСЬ ваш сайт.
Спасибо Петр хорошая статья.
Спасибо. Все очень понятно. Сделал все, как вы написали. Все вроде в порядке=) Еще раз спасибо.
Благодарю за статью, пригодилась.
Здравствуйте, Петр! У меня вопрос по поводу зеркала сайта. В общем дело в том что у меня сайт доступен по двум доменам, один основной, а второй припаркованный кириллический. Будет ли являться припаркованный домен зеркалом, и нужно ли его добавлять в robots.txt
Здравствуйте Петр! У меня проблема в том что если с главной открыть статью кликнув по названию статьи, то открывается нормально сайт.ру/название-статьи.хтмл , а если кликнуть ссылку “Читать полностью”, урл приобретает вид сайт.ру/название-статьи.хтмл#more-123 это получается дубль, никак не могу понять как запретить такие дубли в роботс (пробовал Disallow: *more*, не помгает) или может где-то код надо подправить?
Ребята подскажите почему Яндексу неудается загрузить мой файл robots.txt?Я уже несколько разных шаблонов перепробовал.И в какую папку корня public_html нужно закинуть robots.txt?Заранее спасибо!
Александр, руководствуясь Вашими уроками( спасибо Вам огроменное), я создал сайт по игровым автоматам. Все сделал правильно( на мой взгляд) , но вот в яндексе (уже два месяца сайту) его до сих пор нет. Оптимизацию проверил, робот.тхт Ваш взял , правил вроде никаких не нарушал. Помогите плиззз в чем может быть причина
Статьи уникальные?
Да 92-97% Уже инет облазил на предмет плохой истории домена . Проиндексированные ссылки есть , а в индекс не хочет =(
могу предположить, что сайт под фильтром, судя по косвенным признакам – проверьте в ЯндексВэбМастере состояние индексирования, есть ли карта сайта, а вообще напишите им тех.помощь
Спасибо большое Вы меня спасли
Я месяц лазил в этих дебрях наконец-то нашел вразумительные ответы на свои вопросы .
Все таки тяжеловато быть начинающим, да еще и в одиночку.
Пожалуйста! Спасибо за отзыв!
Спасибо за такую познавательную статью! Я уже установила robots.txt на сайт с помощью вашей статьи))). Подскажите, вот какой у меня вопрос! Почему на моем сайт проиндексирован яндексом всего одна страничка?
Либо сайт слишком молодой, либо АГС…
Либо в старом файле они были закрыты от индексации. Так было у меня – все кричали про АГС, а я поставила из платного курса(!!!) такой файл robot.txt.
Прождите недельки две и посмотрите что изменилось…
Также у меня вопрос к автору:
Пётр, скажите, плиз, это теперь после каждого обновления Вордпресс надо проверять sitemap?
Чуть не пролетела – Гугл перестал видеть карту сайта после автоматического обновления.
Что можно сделать, чтобы избежать этих сюрпризов?
Снова приветствую Вас, Петр. Скажите в файле robots.txt разве нужно указывать карту сайта с расширением xml.gz (архив карты сайта). Если да, то почему? Заранее за ответ спасибо!!!
Петр такой вопрос, как мне закрыть от индексации главное горизонтальное меню? (как у вас Главная
Уроки О блоге Контакты Услуги Реклама Ученики
Использую Карта) Цели)
Пробывал noindex в редакторе но после страница выдает ошибку и не раб. , посоветуйте если знаете.. спасибо
Дополню одну деталь с Вашего позволения. Для робота Яндекса ,при большом трафике на сайте, полезно добавить директиву Crawl-delay: 2 ,где 2 – время в секундах между закачками содержимого страниц поисковым роботом.Время можно задавать на свое усмотрение.Это позволит снизить нагрузку и избежать превышения лимита трафика на сайте.Для Гугла это не имеет значения, так как задается в настройках панели инструментов вебмастера.
А у меня все стоит как описано выше, но робот блокирует страницы (пишет на ваш URL). Не пойму, в чем дело Уже в яндекс вебмастере прописал главное зеркало без www. все равно такая же ерунда. Правда там написано, что изменения вступят в силу через одной – двух индексаций. Посмотрю через пару дней, но что-то надежда слабая.
Петр, спасибо за статью!
А как быть, если у меня сайт был сделан на html, а потом я сделал папку в корне сайта и туда установил вордпресс?
P.S. sitemap будет генерироваться в пределах этой папки?
Здравствуйте, Петр! А как быть, если ЧПУ вида: сайт/2012/01/16/статья
Я новенький в создании сайтов и сделал robots как Вы написали! Вот вопрос, это нормально, что Яндекс пишет исключено роботом 485, с них: Документ запрещен в файле robots.txt – 399 и Документ содержит мета-тег noindex – 85.
А в Гугл: Заблокирован файлом robots.txt – 306.
И с каждым сканированием роботов постоянно увеличиваются ошибки. Это так и должно или я что то не так доделал???
Дайте адрес сайта, где посмотреть файл robots.txt, может Вы сами закрыли доступ робота Google.
У меня – такая же проблема… Яндекс меня не индексирует.
А сейчас объявила конкурс на блоге и многие бояться участвовать… Я прямо в отчаянии…
Проверила свой robot.txt – там есть Disallow: /*?* но у меня присутствует ЧПУ.
Очень прошу Вас посмотреть и подсказать – мало что смыслю в тех.вопросах, но блог очень люблю и вкладываю в него всю душу…
А что сейчас делать – не знаю.
Проверьте в Яндекс Вебмастере: там есть такой раздел “Проверить URL”, потом посмотрите на результаты. Там напишут причину, почему страница не в индексе.
Проверила – причину не пишут…
Пишут, нажмите на слово “Готово” Вот скриншот prntscr.com/30yw2w
Я вчера смотрела это “готово”…
Можно, Вы одним глазиком глянете? На почте.
спасибо, ну я так и не понял это нормально что с каждым сканированием роботов постоянно увеличиваются ошибки. Это так и должно!!!
В принципе Вы можете просмотреть в инструментах вебмастера Гугл, что именно закрыто для индексации, и потом сравнить со своим robots.txt действительно ли они закрыты,и потом уже делать какие либо выводы.
Вот мой сайт:insurance-help.info
Рекомендую, на данном этапе раскрутки сайта не ставить Crawl-delay: 3, у Вас не такая большая посещаемость в сутки, для того, чтобы они создавали нагрузку на сервер. А роботам, как раз, нужно дать волю, и не ограничивать их время пребывания, то есть никаких тайм аутов. На этом сайте посетителей в сутки около 2500 человек, и то Петр не использует Crawl-delay. Также рекомендую для себя взять robots.txt вот этот: http://shakin.ru/robots.txt и добавить в него разрешение индексации картинок: Allow: /wp-content/uploads и закрыть папку хостинга: Disallow: /cgi-bin
На сколько я знаю, то ошибок не должно быть. Единственное, что при анализе сайта, например через Инструменты для веб-мастеров от Google, может быть ситуация, что заблокировано robots.txt (к примеру rss feed) и не найдено контента (если он был роботом проиндексирован, а потом Вами удален). Еще, если Вы решите оставить свой robots.txt, очень рекомендую прогнать через Яндекс. Вебмастер в закладке http://webmaster.yandex.ua/robots.xml, каждый параметр robots.txt и методом тыка вывести тот параметр, который вызывает ошибки. Удачи!!!
и ещё вопрос: у меня стоит ЧПУ, нужно ли в роботс ставить Disallow: /*?*
помогите, пожалуйста, начинающему блогеру 🙂
так получилось, что мной был установлен робот txt до того, как установлена карта сайта. теперь при установке плагина для карты сайта выдается следующее:
пишет:
Установка плагина…
Каталог назначения уже существует.
Установка плагина не удалась.
что делать? удалять робот txt, ставить карту сайта, а потом робот txt ? и как вообще это сделать. дайте алгоритм, пожалуйста!
Это не из-за роботc.txt, а потому что уже был установлен плагин карты сайта. Значит у Вас уже установлен плагин, нет необходимости повторно его устанавливать.
Спасибо, Петр! Буду разбираться!
Здравствуйте, у меня вопрос после закачки robots.txt появляется вторая строчка:
User-agent: *
Crawl-delay: 4
Disallow: /cgi-bin
В исходном ее не было, что бы это значило? Спасибо
Ничего страшного… Это задержка для робота.
У меня и этат робат не пашит че делать?!
здравствуйте Петр! Очень рада, что случайно , из поисковика, попала на ваш сайт. Установила робот. Начала проверять на Яндексе, набрала URL cайта без www, мне написали, что это не мой сайт. Набрала с www. , мне написали, что вход роботу разрешен.
А я писала HOST: dietmag.ru …и т.д. без www
подскажите, пжлста, сделала ли я ошибку, когда прописывала(копировала у вас) код для робота.
Спасибо. Подписалась на новые статьи у вас. Вы очень доступно объясняете. Еще раз, большое спасиб
Может у Вас в .htaccess стоит редирект (перенаправление)?
Петр, спасибо большое за статью и за файл Robots.txt. Если можно, я воспользуюсь Вашим.
Проверила свои статьи через Яндекс вебмастер, все открыто для идексации. Спасибо.
Странно, а почему Вы указываете Sitemap только для Яндекса. По идее путь к карте сайта xml надо указывать в User-agent: *
Sitemap тут указан для всех, может только через пробел его делать – я так сделал. А вот с тегами вопрос – а так уж нужно их закрывать? Ведь на странице тега только начала нескольких статей – в совокупности они не составляют дубль той или иной страницы. Я для эксперимента на одном сайте на запрещал их к индексации, в итоге по некоторым запросам страницы тегов в поиске на первых местах, что привлекает доп. трафик. То же самое с категориями, которые закрываем в плагине. Не знаю может санкции поисковиков и наступят, но пока, тьфу-тьфу, все нормально. Ваше мнение?
Помогите я сделал как вы сказали у меня написали разрешен но сайт еще стоит на запрете (Ваш сайт не был проиндексирован из-за запрета в файле robots.txt) почему так?
Пост полезен на 100%. У меня возникла подобная проблема с индексацией Яши, поэтому для ее решения воспользовался вашим вариантом.
Новичку лучше не заморачиваться где и что прописать. Проще взять готовый шаблон и прописать там свои данные.
Очень доходчиво написано про robots.txt. Воспользовался вашей версией. Спасибо. Но почему-то после заливки его в корень сайта начали индексироваться страницы без контента с одними только фотографиями. Подскажите как это исправить?
Спасибо! Хорошая статья!
Здравствуйте Никита подскажите пожалуйста как стоит поступить. Сегодня Гугл AdSense прислал мне такое письмо ,что некоторые страницы не сканируются роботом
Для исправления такой ошибки он советует добавить в самое начало робот.тхт вот это (User-agent: Mediapartners-Google
Disallow:)
Стоит ли рискнуть для полного сканирования?
Спасибо, все доступно.
Поставил, работает.
Извиняюсь, но при таком роботс.тхт у меня почему-то гугл не индексирует страницы сайта? Только главная, почему? Что не так?
Наконец-то я нашла правильный робот! Спасибо огромное! теперь проблем с индексацией нет!))))
Здравствуйте Пётр, вот только у вас нашёл про запрет записей вроде бы без ЧПУ, у меня как раз та самая проблема, яндекс исключил страницы вида “/?p=769” хотя ЧПУ настроен и самое главное то что когда переходишь по ссылка открывается запись, но уже с нормальным url и такое уже с двумя сайтами, что делать не знаю
Пожалуйста, растолкуйте, что означает в ЯндексВебмастере “Используемые секции”? У меня в результате проверки робот.тхт такие строки появились:
1-3
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
5-5
Sitemap: http://dela-v-dome.ru/sitemap.xml.gz
В окне тоже только они. Как это понять? А остальные строки в роботе не понимаются и не используются что-ли? Или надо наоборот именно эти выведенные строки исправлять? В роботе они без слеша. Статьи и страницы нормально, в зеленом цвете, разрешены.
Еще один вопрос не понятен. В коментах все говорят об индексации. Как ее проверять, если статей на сайте совсем мало и он молодой?
Спасибо огромное за все уроки!! Они мне помогли очень сильно!
Спасибо за информацию.Очень пригодилась
Парняга ты красава реально рубишь!!!!Вот только я так и не сооброжу куда его в конце загружать,и каким способом.
Привет!
Подскажи, а новый робот.тхт когда начнет индексироваться после замены?
Через несколько дней 🙂
А в вебмастере когда увижу проиндексированные страницы ? уже очень хочется 🙂
Кто может подсказать с таким вопросом. Я брал роботс тут и после добавления сайта в ягдекс.вебмастер все стать как бы исключены из-за него, а индексируются только такие как: о блоге, контакты и т.д. Подскажите
Вы настраивали ЧПУ?
[quote comment=”27761″]Вы настраивали ЧПУ?[/quote]
Петр, я уже разобрался спасибо. Поговорил с Яндексом.
Да ЧПУ настроено.
Страницы выпадают из индекса.БЫЛО 70, ОСТАЛОСЬ 9. Стал разбираться, видимо из-за дублирования WP.
Robots.txt выглядит так.
User-agent: *
Disallow:
Sitemap: http://zastolomeda.ru/sitemap.xml.gz
Подскажите, что не так.
Здравствуйте, Пётр! Я сделала всё один-в-один по статье и получилось у меня один-в-один как Вы описали. Только есть одно “но” о котором у Вас в стетье нет информации. В общем все страницы проверила и все разрешены у меня, но всё же присутствует вот такое сообщение (результаты проверки робот.txt -строка) 32: Sitemap: hhttp://мойдомен.ru/sitemap.xml
Некорректный формат URL файла Sitemap
Это страшно? Чем это может обернуть и в чём собственно ошибка?
Пардон, за глупый вопрос. У меня со зрением беда и я не увидела, что в домене 2 раза повторилась “hhttp”теперь всё работает как надо! Афтар просто умничка! Полезный блогчек у Вас, буду захаживать теперь.
Доброго времени суток. Я заранее извиняюсь если не по теме. У меня вот какого рода проблема. В корне блога появился файл с именем error_log Его размер постоянно растет. Заметил что после его появления блог стал периодически падать. Пишет вот такое сообщение (Ошибка установки соединения с базой данных) потом выкидывает на сайт хоста, где написано следующее (CGI script error Ошибка исполнения CGI приложения
Русское описание
Пользователь превысил лимит на количество одновременно исполняемых CGI. В данный момент исполнение невозможно. Попробуйте позже.)
Подскажите пожалуйста в чем проблема? И возможные пути её решения. Заранее благодарю.
Да. и спасибо Вам за столь полезный бложек.
Попробуйте обратиться в техподдержку хостера.
а можно для гугла отдельно прописать? или
User-agent: *
Disallow:
этого достаточно?
Петр, большое спасибо! Уже голову сломала, никак не могла понять, почему в интернет-магазине индексируются все странице, а на сайте в WordPress – ни одна. Причина – Disallow: /*?*. Теперь исправила благодаря Вашему уроку.
У меня следующая проблема. Я в вебмастере яндекса стала проверять свой robots.txt и как оказалось, индексировать разрешено все. Тогда я стала искать предлагаемые варианты на других сайтах, но результат все тот же. Иногда запрещает индексировать категории, а иногда метки. Подскажите, в чем моя проблема? Sitemap сгенерирован плагином Google XML Sitemaps
А Вы данный robots, который я даю, пробовали использовать?
Здравствуйте Петр, у меня состоит проблема в robot txt:
Использовал ваш robot.txt все было нормально. Но буквально неделю назад начало выдавать такое: Документ запрещен в файле robots.txt . Как можно исправить данную проблему? Благодарю за помощь.
Удалить ненужную строку, которая запрещает индексацию.
Подскажите пожалуйста где она именно она находится, так и не понял. Все просмотрел.
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Если у Вас ЧПУ не настроено, нужно убрать строку
Disallow: /*?*
Класс, спасибо за статью, сколько читал другие, не понятно было, а тут всё описано. Автору Респект!
Здравствуйте! Мне тоже показалась очень понятной Ваша статья, за что большое спасибо!
В последних комментариях увидела то, чем сейчас ломаю голову.
Чтобы понятно, вот история вкратце. Яндекс долго не индексировал изначально. Потом мне подсказали, что у меня не правильно прописывается UPL статьи, вместо латиницы было *? как-то так. Исправила в настройках, URLы стали прописываться правильно, Яша стал постепенно индексировать статьи, вначале новые, потом и до старых дошел. Проиндексировал почти 40 страниц и вдруг начал скидывать, по нескольку вначале, а потом все сбросил, кроме одной. Уже недели три разбираюсь.
Яндекс Вебмастер выдает, что страницы не индексируются, потому что запрещено роботом.тхт. Проверяю робот, нахожу строчку Disallow: /?s= Теперь понимаю, что вначале статьи не индексировались именно из-за неё.
Но теперь, когда у меня URLы прописываются правильно, что может быть причиной?
И нужно ли удалить строчку Disallow: /?s=
Проверяю отдельные статьи, как Вы подсказали, ответ РАЗРЕШЕН, но ничего не индексируется.
Буду признательна, если подскажете.
Спасибо за полезный пост. Создал файл, все что надо скрылось. Жду новых уроков 🙂
Вот мой робот
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-trackback
Disallow: /wp-feed
Disallow: /wp-comments
Disallow: /author
Disallow: /checkout
Disallow: /my-account
Disallow: /cart
Disallow: /kontakti
Disallow: /tarifi
Disallow: /drayvera
Disallow: /pokritie
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: */*/feed/*/
Disallow: */comments
Disallow: /category/*/*
Disallow: /*?*
Disallow: /*.php
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-trackback
Disallow: /wp-feed
Disallow: /wp-comments
Disallow: /author
Disallow: /checkout
Disallow: /my-account
Disallow: /cart
Disallow: /kontakti
Disallow: /tarifi
Disallow: /drayvera
Disallow: /pokritie
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: */*/feed/*/
Disallow: */comments
Disallow: /category/*/*
Disallow: /*?*
Disallow: /*.php
Disallow: /tag
Google при добавлении карты пишет что /catalog/ закрыт от индексации!!! Как такое может быть? Host прописан просто не кидал сюда! А Яндекс все нормально кушает и при проверки пишет что этот каталог доступен!
Ребят, есть ли какие либо данные по тому, стоит ли закрывать /tag или нет? Google проиндексировал сайт и там половина контента это тэги, и получается, что задвоение. С другой, стороны Яндекс пишет, что должен быть для людей, а тэги как раз для них.
Стоит закрывать от индексирования. Это дубль.
спасибо за ответ, закрою тогда, пока Яшка не пришел в гости
Здравствуйте Петр. Подскажите, если закрыть Disallow: /tag/, то в панели вебмастера гугл, выходят предупреждения, что доступ к некоторым файлам sitemap заблокирован. Это так и должно быть, он должен писать ошибку?
Файл Sitemap содержит URL, доступ к которым заблокирован в файле robots.txt.
Благодарю
Сделала robots по этой статье. Спасибо! Все понятно расписано…Одну строчку только убрала Disallow: /*?*. И одну добавила. И все индексируется. В прошлый раз у меня не индексировался сайт из-за файла robots…
СРАСИБО ВАМ ОГРОМНОЕ!!!!
Как раз проблема со строкой Disallow: /*?*. Теперь ясно что с этим делать. Спасибо!
Здравствуйте, Петр!
Спасибо за статью!
У меня такой вопрос.
Сделал жене блог на wordpress. У нее много постов, но мало текста, больше картинки. И получается так, что в рубриках весь текст, а где “Подробнее” только дополнительные картинки.
Значит надо как-то закрыть рубрики от индексирования.
Там вложенные рубрики получаются.
Сделал так:
Disallow: /category/
Но еще остается рубрика/подрубрика/статья.
Причем урлы есть как с /category/рубрика/, рак и просто /рубрика/*
Что-то еще надо закрывать тут или нет?
Я бы рубрики даже закрывать бы не стал, ничего страшного.
Петр, уточните ,пожалуйста, еще один вопрос.
у меня wordpress инсталлирован не в корень по принципу:
мой сайт/
а
мой сайт/wordpress/
стоит ли ко всему списку добавлять еще /wordpress/ или бот сам разберется?
Спасибо
Должен “сам разобраться”.
спасибо за ответ
Вообще то хоть немножко разобралась благодаря вам… Тяжело живется чайнкам… А то трафик упал конкретно, может от того, что у меня очень много звуковых файлов, у меня аудио уроки английского. Может папку аудио тоже закрыть?
Поисковые системы не индексируют звуковые файлы.
Спасибо. Век живи, век учись.
Как запретить индексацию страниц.Чтобы не было в поиске page1,page 2.?
Петр, спасибо Вам огромное за статью! У меня самый 1-й сайтик не индексировался гуглом совсем, а я никак причину не могла понять. Оказывается, это из-за ссылок “не ЧПУ”, который я же запретила сама в файле robots.txt. Огромное Вам спасибо, удачи и процветания!
Кто-то может объяснить смысл дублирования правил отдельно для яндекса?
Зачем нужна такая конструкция?
Запретить для всех роботов, включая Яндекс, а потом запретить только Яндексу?
User-agent: *
Disallow: /cgi-bin
User-agent: Yandex
Disallow: /cgi-bin
Привет, вот с таким как у вас файлом в гугле у меня были проблемы, в основной выдаче были теги, а сами записи оказались под фильтром.
User-agent: *
Disallow: /redirect
Disallow: /tag/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/themes
Disallow: /wp-content/plugins
Disallow: /wp-content/languages
Disallow: /wp-content/cache
Disallow: /trackback
Disallow: */trackback
Disallow: */feed
Disallow: /*feed
Disallow: /feed
Disallow: /?feed=
Disallow: /?s=
Disallow: */comments
Disallow: /*comment-page-*
Disallow: /?p
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
Disallow: /search
Disallow: /xmlrpc.php
сделал так – стало лучше.
На последней фото опять Disallow: /*?*
Я установила робот тхт на сайте, но с удивлением обнаружила, что Яндекс и Гугл мои сайт не индексируют. Прочитав урок я поняла, что это из-за ЧПУ. Установила рекомендованный вами файл. Вебмастер Яндекса выдал нормальную картинку, как в уроке. Страницы пока не индексируются, может времени мало прошло. А вот в Гугле по прежнему надпись сканирование сайта запрещено файлом робот тхт. Что делать?
Здравствуйте!
На моём аккаунте гугл-адсенс имеется ошибка сканирования.Выдаёт в качестве ошибки порядка 10 страниц – страницы категорий. Адсенс рекомендует в файл robots.txt вставить свой код, но при этом пишет, цитирую: “Если вы хотите предоставить нашему роботу доступ к своим страницам, то это можно сделать, не давая разрешения на индексацию другим роботам. Просто добавьте следующие две строки в начало файла robots.txt”
Сам код ниже:
User-agent: Mediapartners-Google
Disallow:
У меня вопрос, как к данному коду отнесётся Яндекс? И как можно безопасно устранить ошибку сканирования для адсенса?
Заранее спасибо!
Спасибо, только в вашей статье я нашла причину, почему у меня не индексируется сайт. Очевидно дело в Disallow: /*?* и в том, что у меня не стояло ЧПУ, странно, но другие авторы в большинстве своем не указывают на возможность этой проблемы, а предлагают бодро копировать их вариант robots.txt 🙂
раздел Анализ robots.txt тоже очень полезен!
Спасибо автору за статью
в предо ставленом robots.txt добавил еще Disallow: */category/* Дублей стало меньше.
И закрыли категории) Закрывать нужно не саму категорию, а листинг по категории.
Данный пункт в вашем роботс запрещает индексацию рубрик, лишая ваш блог такого жирного ключа, как “заработок в интернете” (название одной из рубрик, если это ваш сайт указан в профиле…).
Как отдельно листинг закрыть?
Закрывает листинг главной:
Disallow: /page
Закрывает листинг категорий:
Disallow: */page
Работает 100%, можете смело ставить.
В категории можно прописать текст и также их двигать.
Эх.. помню когда свой блог только собирал как какую-то конструкцию из “Лего”, вот тогда Я сильно парился с разными мелочами, ведь очень хотелось создать четкий блог. Что-бы все было сделано четко до мелочей. И вот Я как-то нашел небольшую инструкцию по настройки файла Robots, Я тогда нифига не понял что и как с этим делать и оставил как есть а потом… У одно блогера нашел полезную статью на эту тему и тогда понял что нужно знать! что бы этот файл был настроен на 5+. Здесь кстати говоря! почти все довольно подробно описанно, но можно и лучше!..
Спасибо Вам ОГРОМНОЕ!!!! Наконец-то я справилась с robot.txt и он разрешил просматривать мои страницы. а то я заканчивала курсы по созданию сайтов и там дали мой бывший robot.txt, а он разрешал просматривать только первую страницу. Почему не знаю, но догадываюсь. Спасибо!
Петр, можешь подсказать?
У меня гугл индексирует страницы с медиафайлами типа http://good-seo.ru/ustanovka-denwer-na-windows/ustanovka-denwer-na-windows-4/.
Ты случайно не знаешь, как избавиться от этого?
У меня такой роботс, как написал, проблем не наблюдал, не знаю, к сожалению.
Отличная статья! Столько мучалась с этим, не могла понять, что к чему. А теперь на все сайты сделала, проверила, все работает. Кстати, не в первый раз уже получаю помощь на вашем сайте. Спасибо огромное!
Спасибо за отзыв, Татьяна.
Петр, добавляя Host и Sitemap в конец файла Вы добавляете их только для Яндекса? Или я неправильно понял?
Для Google также
Нет, для всех поисковиков.
Спасибо большая. Вы дали всеобъемлющую информацию по содержанию и проверке файла robots.ru.
Интересно, а с момента написания этой статьи что-то поменялось? Все же она была написана в 2012 году, а сейчас 2014год
Нет, ничего не поменялось, вы можете посмотреть мой robots.txt
Петр, спасибо Вам огромное за Ваш труд! Уже третий сайт делаю по Вашим замечательным урокам. Вот в очередной раз зашла за полезной информацией. Сама плохо запоминаю все тонкости создания сайта с нуля. Зато знаю, где можно их подсмотреть)))) Успехов Вам и Вашим проектам!
Спасибо, Елена, за такие слова. Заходите чаще)
Спасибо за статью!!!
Подскажите, пожалуйста, если я захочу поменять файл robots.txt, можно это делать или лучше работать с тем, что поставлен изначально??? Мой файл немного не такой как у вас.
Вам нужно изучить более детально для чего предназначен этот файл, тогда вы поймете правильный ли он для вашего сайта или нет. Есть ли в индексе поисковиков мусорные страницы или нет.
Думаю, что он у меня правильный.
Все же, если я захочу его поменять, это можно делать или лучше оставить все как есть?
Изменить можно всегда – это не долго. Но нужно понимать что вы изменяете и зачем
как раз сейчас состовляю данный файл. статья помогла !!
User-agent: *
Disallow: /wp-admin/
Sitemap: masters.ee/sitemap.xml
Вот только это и показывает.
Автор пишет: …”А вот из-за этой строчки в robots.txt, у меня перестали индексироваться посты сайта:
Disallow: /*?* …”
И сам же в конце делает картинку, мол это правильный файл и опять же в нем присутствует Disallow: /*?*
хахаха 🙂
Я писал про то, что если на блоге НЕ ИСПОЛЬЗУЕТСЯ ЧПУ то эту строчку не нужно использовать. Читайте, пожалуйста, внимательнее.
Добрый день при проверке
https://www.google.com/webmasters/tools/mobile-friendly/?hl=ru
Не подгружается сss
Может ли это быть причиной что закрыты от индексации
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Конечно, если вы закрыли свои css стили, то робот их не видит
Здравствуйте!
Вопрос, на который не могу найти ответ. Был бы благодарен за Ваше мнение. Мой сайт – не блог, а сайт небольшого агентства недвижимости.
Сайт на WordPress с ЧПУ, я подкорректировал robots согласно рекомендациям, а также примерам на различных сайтах. Наряду с прочими директивами имеются и вот эти:
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Проверяю мои страницы в webmaster Гугла в разделе “Посмотреть как Googlebot”. При таком robors на страницах отображаются только тексты, то есть сайт выглядит как полу-фабрикат. А фотографии, дизайн, элементы оформления, таблицы и т.д. не видны. Указывается, что блокировка этих элементов происходит из-за директив:
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
В этой связи вопрос. Так и должно быть, что сайт выглядит для поисковиков усеченным? Или всё же он будет понижен в результатах выдачи поисковиков из-за того, что он выглядит в их глазах ущербным? Если последнее верно, то что нужно сделать, чтобы исправить ситуацию?
Сергей К.
Оставьте так, все хорошо.
Петр, а зачем вы запрещаете индексацию Disallow: /wp-content/themes и /wp-content/plugins? Это неправильно. В этой папке содержатся css стили, которые должны индексироваться. В Гугле из-за этой строки могут возникнуть проблемы.
Так же хочу добавить, что много строк дублируются. В этом тоже нет необходимости. А так же не закрыта строка поиска от индексации.
А так же не закрыты:
Disallow: /xmlrpc.php
Disallow: /wp-includes/wlwmanifest.xml
Disallow: /xmlrpc.php?rsd
Disallow: /?s=
В целом, это далеко от правильного robots.txt…
Главное, у меня нет ненужных страниц в индексе. А это основное предназначение роботса. Не стоит на нем сходить с ума.
Я их открыл недавно для Гугла, посмотрите нынешний robots.txt моего сайта.
Большое спасибо! Вы мне очень помогли! Была проблема с индексацией страниц со статьями в Яндекс. Долго искал ответ. Нашёл у Вас. Проблема в строке Disallow: /*?*.
Пожалуйста, рад был помочь!
Считаю, что нет единственно правильного файла для всех блогов.
Главное понимать зачем нужен этот роботс, тогда получится его составить без ошибок.
Иногда следует проверять, какие страницы попадают в выдачу яндекса и google и если появляются непонятные страницы, то их необходимо исключать при помощи роботса или другими способами
Правильно. Есть примерные формы. Можно сказать универсальные. Да они будут работать. Но у каждого сайта свои фишки, идеи могут быть. И вот тут роботс приходится изменять.
Здравствуйте, скажите, не будет ли ошибкой добавить в robots.txt для вордпресс: Disallow: /*.php
добрый день.
у меня такая проблема: яндекс из 13 записей проиндексировал только 2. а остальные исключены роботом.
с чем это связано и как можно исправить.
иcпользую robot.txt из этого урока.
Здравствуйте! Спасибо! Я установил плагин All-In-One-Seo, после этого уже месяц статьи сайта Яша не индексирует, хотя проверил они не запрещены для индексирования. Гоша “кушает” с аппетитом. Файлик robots.txt соответствует Вашему
Добрый вечер! У меня такой вопрос.. Нужно ли запрещать страницы типа: “Правила сайта, Обратная связь, Контакты и т.д.. ?
Нет, не нужно запрещать.
А если у меня нет папок и адресов /trackback/, то всё равно указывать это в роботс для исключения индексации?
И если у меня одна стаья доступна по двум адресам:
к примеру по адресу …/bulls/ и …/2016/03/, то не могу же я каждый раз блокировать /2016/03/, /2016/04, /2016/05 и т.д.?
Нужно как-то по другому постоянные ссылки настроить?
У меня там поля “Префикс для рубрик” и “Префикс для меток” пустые.
Здравствуйте! Подскажите, пожалуйста, куда заливать этот файл в вордпрессе? В консоли есть папка мультимедиа, но туда не заливается. А других папок, куда можно чт-то загрузить, – нет.
Здравствуйте, пожалуйста ответьте. Сайту еще нет месяца, настроил robots.txt, создал карту сайта, сам robots.txt выглядит вот так. Все прописано, адрес сайта тоже прописан.
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-content/cache
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Host:
Sitemap: http://
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Все бы хорошо, вот только статьи на сайте не индексируются гуглом. При поиске той или иной страницы она выдается, но статья на сайте составляет 100 % уникальности, как будто робот гугла индексирует только урл страницы и ключевые слова, а статья остается не тронутой. Я даже пытался индексировать статьи Googlebot, но она через несколько часов снова вылетала из индекса, хотя при поиске гугла все ключевые слова страниц показываются.
Очень прошу ответьте, заранее благодарен.
в разделе яндекс пишет, Страница известна роботу, но отсутствует в поиске. Возможные причины ее отсутствия описаны в Помощи.
Проверьте meta name robots в исходном коде, там может быть noindex
Здравствуйте Петр. Ни как не могу разобраться вот в чем: допустим я захотел закрыть рубрику от индексации(чтобы было поменьше дублей), я прописываю Disallow: /рубрика1 , а будут ли тогда индексироваться сами статьи который находятся в этой рубрике и имеют адрес мойсайт/рубрика1/статья1 ?
Для всех сомнительных подобных моментов я рекомендую использовать специальный инструмент в Яндекс Вебмастере, называется Анализ robots.txt. Туда вбиваете свой robots.txt, который хотите создать и ниже url, у которых хотите проверить: будет индексироваться или нет.
Подскажите пожалуйста , я не создавал robots.txt но у меня есть уже строки:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Если создавать robots.txt то он перекрывает плагин Google XML Sitemaps.
Как поступить лучше в этой ситуации?
Петр, большое спасибо за статью!
Сейчас на сайте у вас совсем другой robots.txt – его лучше скопировать или тот, что вы указали в статье?
Лучше разобраться какая строчка за что отвечает )
Да, это, на самом деле, самый полезный совет ))
Пётр, скажите, пожалуйста, что запрещает вот это
Disallow: /poisk ? Запрещает индексацию результатов поиска на сайте?
Это закрывает страницу поиска на моем сайте, поэтому она есть. Можете убрать эту строчку у себя
Петр, здравствуйте! Вот такой страницы ( Sitemap: https://reclampa.ru/sitemap.xml) у вас в карте сайта нет, но в роботс.тхт вы ее указали. Вы изменили роботс.тхт или нет?
Да, изменил robot.txt
Ребята, не закрывайте для гугл бота /wp-content/themes и /wp-content/themes он перестает видеть адаптивность страниц из-за блокировки файлов CSS. проверьте сами в серчь-консолях, хотя чндекс по прежнему видит их адаптивными
Добрый день!
Очень полезная статья для новичка!!! Это мои первые шаги, и до установки робота по вашему совету, Яндекс не хотел даже открывать мой сайт, после того, как я произвел все манипуляции, о которых Вы пишете, все ЗАРАБОТАЛО!!!))) Спасибо Вам огромное и удачи!!!
Паш привет, я фанат твоих работ, спасибо за них! Вопрос: Я заметил у тебя в яндексе несколько страниц проиндексированно которые просто пустые страницы с одной фото (яндекс фото как отдельную страницу индексирует) – у меня такая же проблема, как я понял ты както другие фото исправил так как у тебя не все фото так заиндексированны – 1) Стоит ли скрыть такие страницы -пустышки- из индексации? 2) Как это сделать? (seo yoast не дает варианта, при вставлении медиафайла я выбираю -ссылки нет- но все равно она создается и индексируетса, если заблокировать uploads папку то тогда все картинки не попадут в индексацию вообще как я понал), что делать? помоги плиз
В Yoast SEO просто нужно поставить галочку в настройках напротив attaches
Футы, изивни не Паш а Петь, заматался тут немного
Добрый день. Влияет ли запрет Disallow: /wp-content/themes и так далее на продвижение? Поясню. В серчконсоле гугла добавляю на индексацию страницу, жму получить и отобразить. Собственно высвечаивается скрин как страницу видит бот. Страница выходит убогой, потому что для бота закрыт доступ к скриптам и даже к style.css, который находится в директории вп контент. Внизу написано, что заблокировано. Собственно вопрос, а влияет ли это каким-либо образом на индексацию, либо же все хорошо и роботу нет разницы.
Привет Петь. Первый раз тебе пишу. И первый раз создал сайт на вордпресс по твоим урокам. Это было, если быть точным в 2012 году. Очень тебе благодарен за все и за твои уроки. Сейчас новый проект создаю и у меня возник вопрос следующего содержания.
Я установил карту xml думаю уже на следующий день пропишу robots.txt, как мне на глаза попадается плагин Yoast SEO. Я ознакомился с функционалом действительно отличная штука.
Так вот я установил его и активировал. И он мне сразу выдает, что может быть конфликт с плагином sitemap xml. Потому что он тоже создает карту. И он предлагает мне его удалить.
Как быть отключить xml плагин?
Ах, да и еще. Когда устанавливал sitmap xml – он попросил удалить два файла sitemap. Сейчас они уже не работают там что-ли и не надо их в корневую папку прописывать. Они где-то автоматически прописываются, если в файле robots все равное есть путь к ним? Благодарю за все еще раз )
Спасибо, то, что нужно!
Спасибо!!!
спасибо за объяснение!
Вот в этой статье автор утверждает о том, что если открыть uploads для всех ботов, то в индексе появляются загруженные PDF и прочие текстовые файлы. А в яндекс вебмастере, в отчете “Исключенные страницы” появляются сообщения об ошибке при индексировании картинок, мол содержимое не поддерживается. Вот и не знаю кому верить…