
Привет! На прошлом уроке я рассказал вам, как выявить и проверить переспам и переоптимизацию страниц на сайте. В этом же уроке продолжим, расскажу, что нужно делать со всем этим и как бороться.
Как избавиться от переоптимизации страниц сайта
Вот типичная картина переоптимизированности страницы:

Забегая вперед, хочу сказать, что это резкое падение страницы связано с внедрением алгоритма “Баден-Баден”. Про алгоритм Яндекса “Баден-Баден” мы еще поговорим в ближайшем уроке, но по сути “Баден-Баден” был внедрен для борьбы с переоптимизацией.
Если посмотреть, позиции, то ярко выражено резкое падение (обращайте внимание только на позиции по Яндексу):
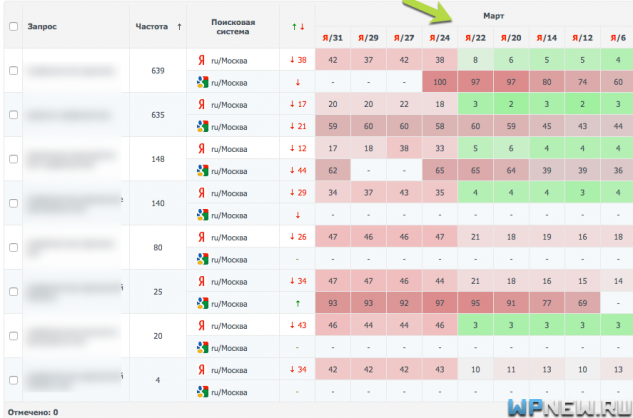
Невооруженным глазом можно наблюдать резкий обвал всех запросов на странице . И тут, я полагаю, всем понятно, что Яндексу явно что-то перестало нравиться и это надо исправлять, чтобы снова попасть в ТОП.
К сожалению, в данном случае Пиксель Тулс (напомню, на прошлом уроке мы искали подобные страницы с помощью данного инструмента) показал, что на странице нет переоптимизации. Попробовал вручную с помощью операторов site посмотреть, что выдаст Яндекс, в итоге ничего. Тоже самое уже отметили в комментариях к прошлой статье:
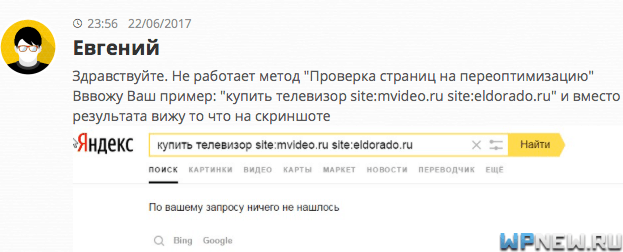
Стоило мне написать прошлый урок, как Яндекс сразу же убрал возможность проверить переоптимизацию таким способом. Возможно “Яндексоиды” читают мой блог? xD
По ходу Пиксель Тулс тоже делал выводы о переоптимизации с помощью данного операторов, потому что эта страница тоже никак не отображается переоптмизированной.
Вообще, если переоптимизация обнаружена Pixel Tools в экспертной функции, то сервис еще даст рекомендации что делать, что-то в этом роде:
![]()
Но, к сожалению, в данном случае Пиксель Тулс отобразил страницу так, как будто на ней нет переоптимизации и поэтому список правок не получил. Чуть ниже я показал, как можно другими способами найти то, что стоит подправить.
Вот еще очень хороший сервис проверки на переоптимизацию от Arsenkin (бесплатно), вот он показал, что вероятность фильтра 99%, а это уже намного ближе к правде. 🙂

Жаль только вот рекомендации не дает по корректировке страниц.
Как избавиться от переспама в запросах
Вот, например, в съемщике позиций я четко вижу, как у меня просел запрос. Причем остальные запросы этой страницы находятся в ТОПе.
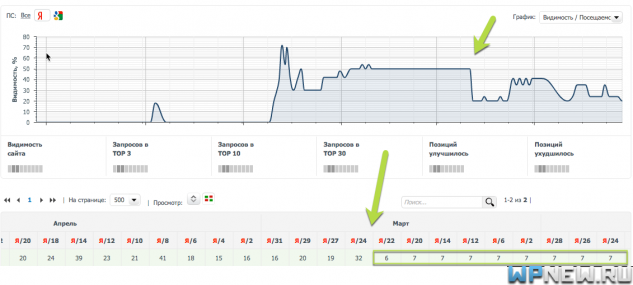
После того, как нашли переспамленный запрос, нужно понять что с ним делать. Конечно, можно на глаз изучить страницу и постараться понять, что не так с запросом и где находится переспам (а иногда и “недоспам”). Но это не всегда легко заметить (я исключаю явные случаи, когда ключи чуть ли не в каждом предложении).
Например, был случай: как-то создавалась страница по низкоконкурентному запросу. Статья была лучшая в рунете на момент публикации по всем параметрам, но по истечении месяца основной запрос так и не попал даже в ТОП-100. Конечно, это насторожило, изучая страницу, показалось что все-таки много выделений было жирным (хотя жирным ключевые слова не выделяли, а просто фразы по смыслу и для удобства в визуальном восприятии). Была переоптимизация.
Просто убрали эти выделения жирным, и вуаля, через пару недель страница залетела на 7-ую позицию по основному запросу, а после прочно закрепилась в ТОП-3 надолго (за счет поведенческих факторов), даже когда конкуренция по запросу сильно выросла. Вообще, я рекомендую не делать много всяких выделений в тексте, даже если это не ключевые слова. Если прям очень надо, лучше обойтись CSS, без излишнего использования тегов strong, i и др.
Но, к сожалению, не всегда на глаз удается найти проблему на странице. Для дополнительной помощи можно воспользоваться сторонними сервисами.
К примеру, можно воспользоваться сервисом Seolib.
- Во вкладке “Инструменты” находим раздел “Релевантность текстов”:

- Вбиваем ключевое слово и обязательно ставим галочку напротив “Сравнить ТОП со своим сайтом”, указываем наш целевой URL:

- На выходе мы получаем таблицу в виде сравнение ТОПовых страниц с нашими, вот что получилось:
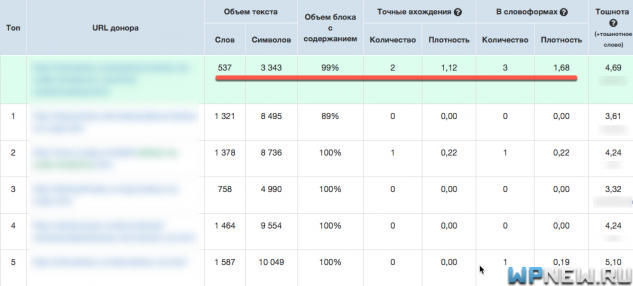
- Обратите внимание на подчеркнутое красным. Видно, что по контенту у нас объем текста маловат, я бы добавил текста побольше. Количество точных вхождений запроса – слишком много, да и количество вхождений в словоформах (ключевые слова в разных падежах) – аналогично, перебор. Мы, по сути получили список рекомендаций того, что нужно сделать со страницей, чтобы избавиться от переспама. Там же отображаются наши “переборы”/”недоборы” по ключам в Title, Description, заголовках h и др.
Помимо SEOlib есть еще очень много других инструменты, например текстовой анализатор от Just Magic. Очень качественный с технической точки зрения, но вот “человечности” сервису явно не хватает. Чтобы пользоваться данным сервисом вам нужно будет не один раз прочитать документацию, причем очень внимательно. На выходе получите, что-то вроде этого:

Также, подобное есть и в Rush Analytics (про кластеризацию запросов с помощью Rush Analytics я уже рассказывал). Вот полная инструкция, как пользоваться текстовым анализатором. На выходе получится файл, но уже более понятный простому “смертному” 🙂 :


Помимо этих сервисов, есть еще функционал в GoGetLinks, который мне тоже нравится. Выглядит он таким образом:
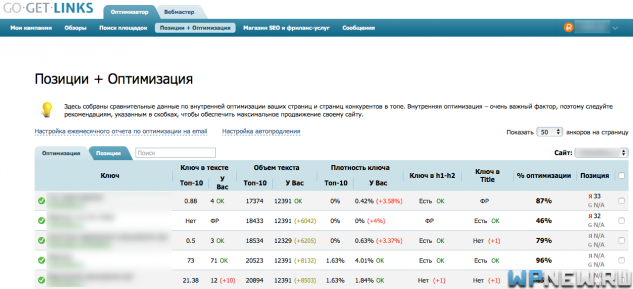
Поиск причин переоптимизации вручную
Если же вдруг у вас нет возможности/желания пользоваться подобными сервисами или хотите получить более точные данные, можно все это дело сделать вручную (данный ручной метод мы до сих пор применяем для очень важных запросов). Алгоритм следующий:
- Берем наш самый основной запрос, вбиваем его в нашем регионе в браузере в режиме инкогнито.
- Выписываем ТОП-10 URL в таблицу.
- Берем тексты с этих сайтов, прогоняем их с помощью SEO анализа текстов в Адвего.
- “Выдергиваем” метатеги и заголовки h1 у сайтов, обязательно обращаем внимание на количество повторений ключевых слов, наличия точного/разбавленного вхождения, длину.
- Заполняем следующие данные в таблицу: объем контента, какие фразы встречаются чаще (берем во внимание не только основные ключи, но и дополнительные, расширяющие семантику статьи), количество повторений.
- Если у вас интернет-магазин, рекомендую еще обязательно обращать внимание на то, как выводятся список товаров на страницах “листингах” (категории, метки и пр.), какие ключи используются в них, сколько товаров выводятся и т.д.
- Найти средние значения. Причем, если в таблице из 10 url будут пара страниц, которые сильно выбиваются из средних значений других сайтов, то такие урлы лучше исключить из анализа сильноискаженного параметра.
Получится что-то вроде этого:

Заключение
Вы должны понимать, что если бы мы не мониторили позиции, то с такой легкостью не нашли бы переспам и переоптимизацию. Мы просто потеряли бы трафик, который конвертируется в деньги. Поэтому, я настоятельно рекомендую регулярно производить съем позиций сайта.
Текстовые анализаторы хороши, но не стоит слепо все делать по их указаниям. Их стоит рассматривать как дополнительный инструмент, который дает подсказку. Заморачиваться, чтобы все на 100% было как в их рекомендациях – не стоит. Пробовали, экспериментировали. Куча потраченного времени и денег, от обычных SEO-оптимизированных текстов разницы в позициях нет. И помните, что сайты в ТОПе постоянно меняются.
Ну вот и все. Вы делаете необходимые правки, которые требуются для того, чтобы убрать переспам и/или переоптимизацию и молитесь ждете изменений. Как правильно и когда лучше оценить изменения на сайте/страницах я расскажу уже в одном из самых ближайших уроков. Оставайтесь на связи! 🙂



{kind=link}
{kind=link}
Интересные моменты ты затронул! Спасибо за информативную статью, очень поможет мне в работе.
Рад был помочь)
Спасибо вам за статью… Я уже давно использую сервис гогетлинкс… Кажется менее затратный в отличие от других…
Данных GoGetLinks не всегда бывает достаточно)
интересная статья. в последнее время применяю последний способ с 10 сайтами топа. значит правильно делал. но позиции не снимаю.
При анализе ТОП-10 не забывай ориентироваться на семантическое ядро тоже, а то можно из-за конкурентов упустить парочку вкусных запросов. Позиции все же рекомендую снимать
К сожалению до конца так и не понятно, за что же идёт наказание, за точные вхождения, за ключевые слова из этого вхождения или всё вместе? Анализ топ 10 вообще не информативен, так как у кого-то каждое слово из фразы 1-2%, у кого-то 3-4, у меня 2-3, а я улетел с 5-го места на 46-е, спрашивается, с какого? Большинство статей содержат в себе 2 точных вхождения, 1-е в начале, 2-е в конце, иногда есть склонённое в середине, объём статей 1500-3000 символов. Правлю ряд статей, и уже грешу на недоспам, так как некоторые слова из вхождения, местами менее 1%. Иногда срабатывает просто убрать 1 точное вхождение и запрос с 46-го места поднимается на 12, но не всегда… Кстати, что вы думаете по поводу суммы ключевых слов из фразы? Вот запрос – желе из красной смородины на зиму. Сколько в сумме должны иметь эти слова? Кто-то пишет каждое слово до 5%, кто-то, что все 4 слова 5-7%. Фразу убрать не проблема, но если не срабатывает, как не переборщить с убиранием слов из фразы? В принципе если будет недоспам, арсенкин вряд-ли покажет фильтр типа 99%? Что скажете? Извините если сумбурно. Спасибо.
Все вместе. Тут все очень сложно. Тяжело в некоторых случаях сказать недоспам или переспам, просто пробовать корректировать. По поводу конкретных процентов частотности: универсальной цифры нет, в каждой тематике по своему, даже я бы сказал, по каждому запросу в разнобой + очень много других факторов (не раз наблюдал, как в ТОПе сидит сайт с кучей выделенных жирным ключевых слов, други факторы перевешивали в данном случае)
Петр, ты где пропал?
У меня была свадьба, потом свадебное путешествие и т.д. 🙂 На блог никак не мог писать, к сожалению.
Пётр, приветствую!
Вопрос такой, будут ещё марафоны? Когда ориентировочно следующий?
Готовлюсь во всю. Ориентировочно в начале ноября старт. 🙂
Спасибо за урок. Узнал новые причины переоптимизации и как можно их вычислить.
Рад был помочь, спасибо)
Спасибо, ваша статья оказалась очень полезной. Но вот возникли вопросы по поводу поиска причин вручную. Например, у меня ключ “ремонт окон”, вы советуете анализировать конкурентов в топ-10, но в топ-10 по этому ключу не всегда у конкурентов стоят релевантные страницы, то есть в выдаче страницы с ценами, регулировкой или ремонтом пластиковых окон, в то время как мне нужны только по ремонту окон. Так вот, стоит ли ориентироваться на показатели этих страниц?
Я бы ориентировался бы больше только на релевантные страницы.
Проследовала всем рекомендациям по проверке страницы на фильтр. Сервис Арсенкина показывает большую вероятность фильтра. А в сеолиб в релевантности отчет в целом не показывает (недо)переоптимизацию. Получается, что вроде фильтр есть, но за что не ясно. Явной переоптимизации нет, в сравнении с конкурентами страница сильно не выделяется по показателям, но упорно висит где-то на 80 позиции. На что еще вы обращаете внимание в таких случаях? Спасибо.
Попробуйте скорректировать текст в одну сторону, выждите 2-3 недели, снимите снова позиции и сравните, если все плохо, потом попробуйте подправить текст в другую сторону и снова сравните позиции
Вот только нашел Ваш сайт, урок, что был нужен. Буду листать назад, подозреваю, многое пригодится, спасибо!
Доброго времени суток Петр, я так и не понял, что на что влияет, у меня был пере спам точно – посадочные страницы падали как только могли, убрал несколько точных вхождений со страницы, запросы стали вроде как подниматься, но (в разных сервисах по разному ) в кк – одни релевантные страницы, в алпозишане другие релевантные страницы, в PositionMeter другие, пиксель тулс другие но больше сходится с тем что у запросов поменялась релевантная страница. я так понимаю что в данном случаи все таки есть фильтр. (описаные выше методы, пробовал, но то ли я что-то не так сделал или же там не сработало)
Скорей всего из-за того, что какой-то сервис работает через XML, а какой-то напрямую. Обычно таких проблем не наблюдал, мы работаем в Топвизоре и там вполне корректно отображаются релевантные страницы в выдаче.
Отлично !
Мне нравится инструмент для проверки на фильтры от Арсенкина, но паралельно проверяю еще через несколько сервисов 🙂
Узнал новые причины переоптимизации и как можно их вычислить.