
Кластеризация запросов семантического ядра – это группировка ключевых слов, которые идут просто списком, разделение их на кластеры (группы). Это то, что превращает тысячу ваших запросов в полноценную структуру, разбитую на категории, страницы, статьи и т.д. Без правильной разбивки вы будете тратить много денег и времени в “холостую”, так как некоторые запросы не могут быть “посажены” на одну страницу. Либо наоборот, ключевые слова требуют, чтобы данные запросы были на одном URL.
При сборе семантического ядра (СЯ) я обычно делаю кластеризацию руками, с помощью Key Collector, вот ссылки по теме:
- Как составить правильную структуру сайта
- Как составить семантическое ядро – Часть 1
- Как составить семантическое ядро – Часть 2
- Что делать с семантическим ядром сайта?
- Как расширить СЯ с помощью общих ключевых слов конкурентов.
Но все это легко и просто, когда у нас есть четкие группы запросов по разному логическому смыслу. Мы прекрасно знаем, что для запроса “Коляска для близнецов” и “Коляска для мальчика” должны существовать разные посадочные страницы.
Но бывают запросы, которые разделяются между собой не совсем явно и тяжело “по ощущениям” определить, какие запросы нужно сажать на одну страницу, а какие запросы раскидывать по разным посадочным URL.
Один из участников моего SEO марафона задал мне вопрос: “Петя, как быть с этими ключами: сажать все на одну страницу, создавать несколько, если да, то сколько?” А вот и сам отрывок из списка ключевых слов:
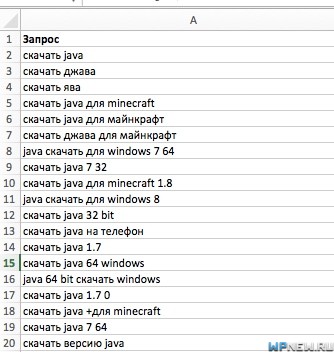
Одно только слово “java” использует в трех вариациях (“ява”, “джава”), плюс ко всему этому народ ищет его для разных игр, устройств и т.д. Запросов там очень много и реально тяжело понять, как все-таки лучше поступить.
Как вы думаете, как правильно? Верно. Лучше всего подойдет анализ конкурентов, которые уже находятся в ТОПе по данным ключевым словам. Сегодня я расскажу вам, как можно сделать кластеризацию семантического ядра на основе данных у конкурентов.
Если у вас уже есть готовый список ключевых слов для кластеризации, вы можете сразу переходить к 4-му пункту.
1. Матрица запросов
Возьму еще другой пример: есть у меня один клиент с интернет-магазином электро- и светотехники. У магазина очень большое количество товаров (несколько десятков тысяч).
Конечно, у любого магазина есть товары, которые наиболее приоритетны для продажи. У этих товаров может быть высокая маржинальность, либо просто нужно избавиться от данного товара со склада. Так вот, пришло мне письмо, что-то вроде этого “Петя, вот список товаров, которые интересны нам”. И там списком было перечислено:
- выключатели;
- светильники;
- лампы;
- прожекторы;
- удлинители;
- и еще несколько пунктов.
Я попросил составить так называемую “матрицу запросов”. Так как владельцы магазина лучше меня знают свой ассортимент, мне нужно было собрать весь товар и основные характеристики/отличия у каждого товара.
Получилось что-то вроде этого:
| Товар | Бренд | Уточнение | Хар-ка | Цена | Транзакция |
|---|---|---|---|---|---|
| удлинитель | iek | на катушке | 10 м | оптом | купить |
| иэк | на колодке | 20 м | недорого | интернет-магазин | |
| universal | бытовой | 30 м | дешево | ||
| универсал | 40 м | ||||
| меркурий |
При составлении матрицы, не забываем, что некоторые англоязычные бренды запрашиваются и на русском, это нужно учесть и их добавить.
Конечно, если у товара были еще и другие характеристики добавлялся столбец. Это могут быть “Цвет”, “Материал” и т.д.
И такая работа была проделана для самых приоритетных товаров.
2. Перемножение запросов
Дальше нужно было сгенерировать всевозможные запросы из этих слов методом “перемножения”. Вручную перемножать эти запросы друг на друга – неэффективная трата времени.
Для перемножения запросов существуют много сервисов и программ. Я воспользовался этим генератором ключевых фраз http://key-cleaner.ru/KeyGenerator, вбиваем туда все наши запросы по столбцам:

Сервис перемножил всевозможные варианты со словом удлинитель. Важно: многие генераторы перемножают только подряд идущие столбцы, то есть 1 столбец со вторым, потом первые два с третьим и т.д. А этот перемножает все подряд из первого столбца с другими: первый со вторым, потом первый с третьим, четвертым; далее первый*второй*третий, первый*второй*четвертый и т.д. То есть мы получаем максимальное количество фраз с содержанием основного слова в первом столбце (это так называемый маркер).
Маркер – это основная фраза, от которого нужно генерировать ключ. Без маркера невозможно создать адекватный ключевой запрос. Нам не нужны фразы “иэк оптом”, или “на катушке купить”.
При перемножении важно, чтобы в каждом ключевом словосочетании был этот маркер. В нашем примере – это фраза “удлинитель”. В итоге сгенерировалось в данном примере 1439 (!) уникальных ключевых фраз:

3. Очистка запросов от “мусора”
Теперь есть 2 варианта развития событий. Можно заняться кластеризацией всех этих запросов и насосоздавать огромное количество сгенерированных страниц под каждый кластер, если позволяет это сделать система вашего сайта. Конечно, у каждой страницы должны быть свои уникальные метатеги, h1 и т.д. Да и проблемно иногда подобные типы страниц засовывать в индекс.
У нас же подобной возможности в техническом плане не было, поэтому мы даже не рассматривали данный вариант. Нужно было в “полуручном” режиме создавать только самые необходимые новые посадочные страницы.
Что дальше делать? Конечно, удалить весь список от мусора. Что является мусором в данном случае? Пустышки. Просто загоняем в Кей Коллектор весь данный список и снимаем частотности по нашему региону.
С каким типом частотности работать? Так как у нас список товаров + пересечений встречались не очень популярные (узконаправленные), я делал акцент на частотности с кавычками (без восклицательных знаков) – то есть в различных словоформах. Это ключевые фразы в разном падеже, числе, роде, склонении. Именно этот показатель позволяет более менее оценить трафик, который мы сможем получить из Яндекса в случае попадания в ТОП.
Снимаем в Key Collector частотности в кавычках у данных фраз (конечно, если у вас сезонный товар, то нужно снять частотности в “сезон”):
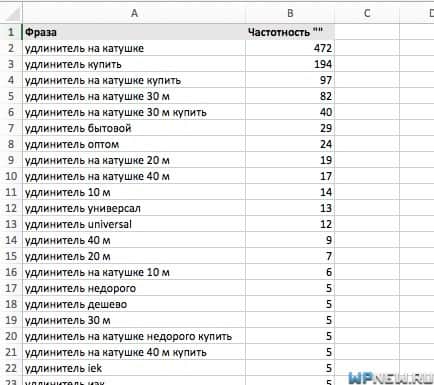
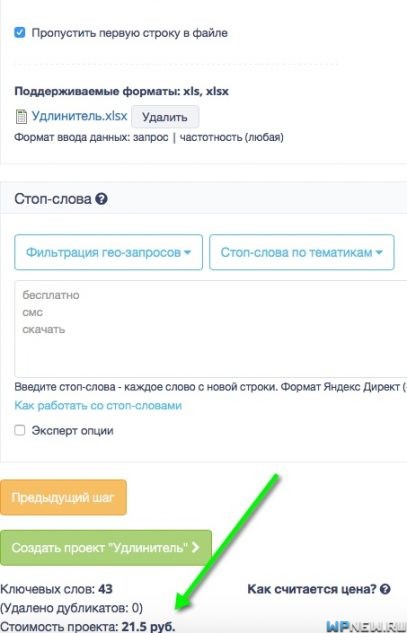
И удаляем все то, что равно нулю. Если у вас более популярная тематика и очень много слов с ненулевой частотностью, вы можете увеличить нижний порог до 5, или еще выше. У меня же ненулевых запросов из 1439 фраз осталось всего 43 по региону Москва и область.
Эти 43 фразы с данными частотностей я переношу в Excel:
4. Кластеризация запросов
Дальше нужно заняться кластеризацией ключевых слов. Я уже описал метод в начале статьи, продублирую: кластеризовывать запросы будем на основе конкурентов.
Все это я делаю в Rush Analytics, вот алгоритм кластеризации в данном сервисе:
Под каждый запрос “выдергивается” из выдачи ТОП-10 URL по заданному региону. Далее по общим URL происходит кластеризация. Точность кластеризации можно задать самому (от 3-х до 8 общих url).
Допустим мы выставили точность 3. Система запоминает URL страниц, которые в ТОП-10 по первому запросу. Если по второму запросу из списка в ТОП-10 встречаются те же 3 URL, которые были у первого, то эти два запроса попадут у нас в 1 кластер. Количество общих URL зависит от заданной нами точности. И такая обработка происходит с каждым запросом. В итоге ключевые слова разбиваются на кластеры.
- Заходим в RushAnalytics -> Кластеризация, создаем новый проект (при регистрации каждый получает 200 рублей на счет для тестирования, удобно):
- Выбираем приоритетную поисковую систему для нас и регион:
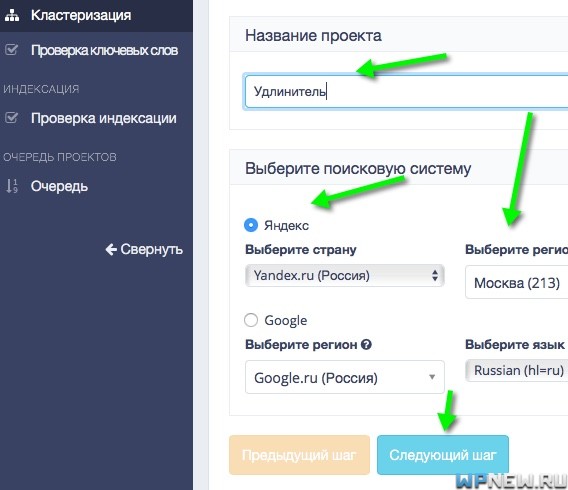
- Выбираете тип кластеризации. Я выбираю в данном случае “Wordstat”. Метод “Ручные маркеры” мне не подходит, так как в запросах только один маркер “удлинитель”. Если же вы загружаете сразу несколько разных типов товаров (пример, удлинитель, лампочка и т.д.), то тогда вам лучше выбрать тип “Wordstat + ручные маркеры” и указать маркеры (маркеры нужно будет отметить цифрой 1 во втором столбце, а не маркеры цифрой 0, частотность уйдет в третий столбец). Маркерами будут самые основные запросы, которые логически никак не связываются между собой (не может “посадиться” запрос “удлинитель” и “лампочка” на одну страницу). В моем случае я работаю поэтапно с каждым товаром и создавал отдельные кампании для удобства. Также выбираете точность кластеризации. Если пока не знаете какой метод выбрать, можно отметить все (на цену это не повлияет никак), а дальше уже после получения результата сможете выбрать тот вариант, который лучше всего откластеризовал ваши запросы. По опыту скажу, что самый подходящий во всех тематиках – это точность = 5. Если вы делаете кластеризацию для уже существующего сайта, я рекомендую вам вбить URL вашего сайта (если ваш сайт будет в ТОП-10 по запросу, то ваш URL выделится зеленым в полученным файле):
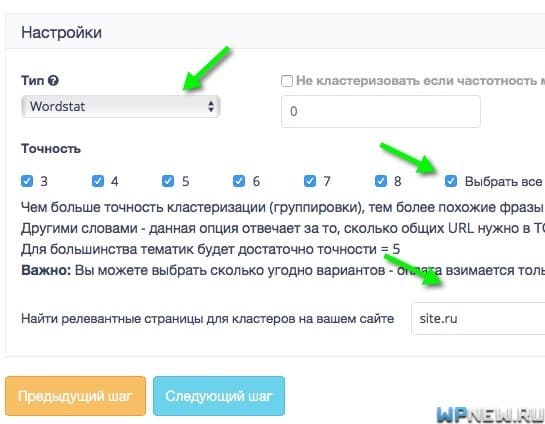
- В следующем шаге загружаете файл в систему. Также можно настроить стоп-слова, у меня же файл был без них, поэтому данная функция не нужна в данном примере. Цена кластеризации – 50-30 копеек за 1 запрос (зависит от объема):
- Нужно будет немного подождать пока сервис Rush Analytics выполнит свою работу. Заходите в завершенный проект. Уже там можете просмотреть кластеры исходя из точности кластеризации (жирным выделено начало нового кластера и его название):
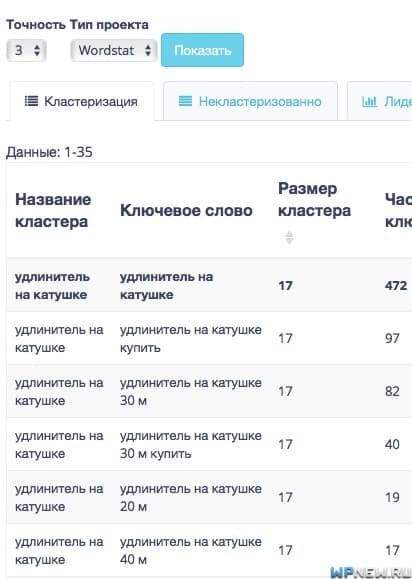
- Повторюсь, лучше всего использовать точность 5 для кластеризации. Он чаще всего подходит.
- Также в соседней вкладке можно увидеть список некластеризованных слов:
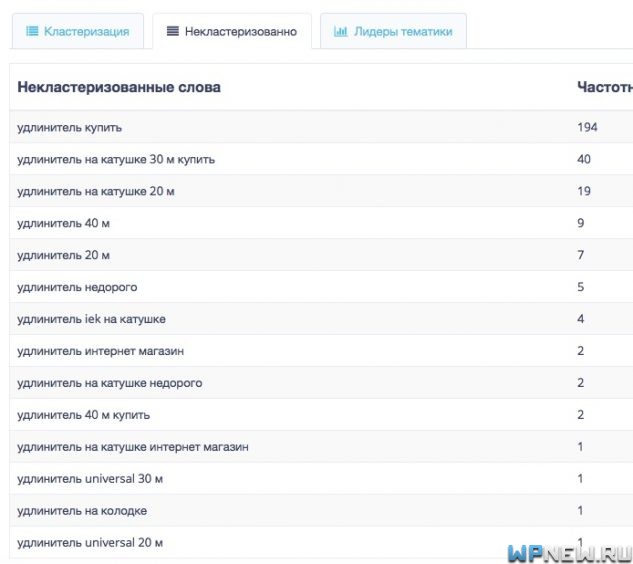 Вы спросите, почему они не кластеризовались? Скорей всего по данным запросам выдача не очень качественная и невозможно было в автоматическом режиме отнести данные запросы к какому-нибудь кластеру. Что с ними делать? Можно кластеризовать вручную и создать отдельные посадочные страницы по логике, если это возможно. Можно даже для одного запроса создать отдельный кластер и “посадить” его на отдельную страницу. Либо же можете расширить список слов и заново произвести кластеризацию в сервисе Rush Analytics.
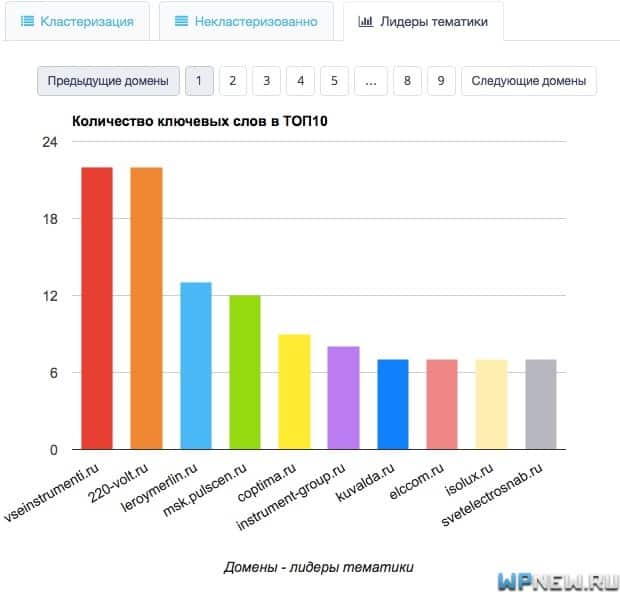
Вы спросите, почему они не кластеризовались? Скорей всего по данным запросам выдача не очень качественная и невозможно было в автоматическом режиме отнести данные запросы к какому-нибудь кластеру. Что с ними делать? Можно кластеризовать вручную и создать отдельные посадочные страницы по логике, если это возможно. Можно даже для одного запроса создать отдельный кластер и “посадить” его на отдельную страницу. Либо же можете расширить список слов и заново произвести кластеризацию в сервисе Rush Analytics. - Во вкладке “Лидеры тематики” можно увидеть ТОПовые домены по данным запросам:
- Кстати, в некоторых запросах вы можете увидеть вот такие пальчики вверх, выделенные “зеленым”:
 Это означает что по данным запросам, у вас уже есть посадочная страница для данного кластера в ТОП-10 и нужно работать над ней.
Это означает что по данным запросам, у вас уже есть посадочная страница для данного кластера в ТОП-10 и нужно работать над ней. - Все это дело можно скачать себе на компьютер в Excel и работать уже в данном документе. Я работаю с точностью 5, поэтому скачиваю этот файл:
- В Excel документе та же самая информация. Серым выделено начало каждого кластера и его название (кликните по изображению, чтобы увеличить):
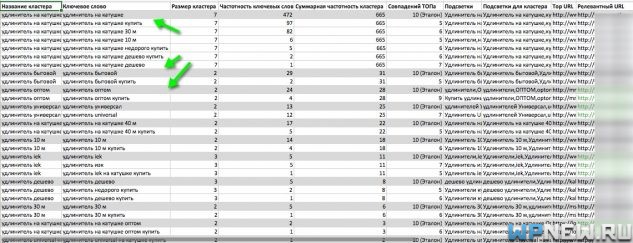
- Помимо названия кластеров, здесь вы увидите их размеры, частотности, суммарные частотности, Top URL, релевантный URL и подсветки, что очень нужно при работе над посадочной страницей. Вот они:
 Обратите внимание, что бренд “Юниверсал” (через “Ю”) тоже подсвечивается, а я даже не подозревал, что данный бренд можно прописывать итак. В подсветках также вы увидите синонимы и тематические фразы, которые крайне желательно использовать на посадочных страницах для достижения ТОПа.
Обратите внимание, что бренд “Юниверсал” (через “Ю”) тоже подсвечивается, а я даже не подозревал, что данный бренд можно прописывать итак. В подсветках также вы увидите синонимы и тематические фразы, которые крайне желательно использовать на посадочных страницах для достижения ТОПа.
Заключение
Что же дальше? Что нам даст эта кластеризация? Теперь под каждый кластер у нас на сайте должен быть отдельный, а главное релевантный url. Продвижение этих страниц полностью в наших руках и продвигаем дальше так, как умеем (оптимизация контента, внутренняя перелинковка, внешняя оптимизация, социальные факторы и т.д.).
Если же мы бы сделали неправильную кластеризацию, то очень много запросов тяжело было бы продвинуть. Это было бы “якорем”, который сдерживал бы нас, несмотря на то, что мы тратили бы кучу денег на продвижение этих страниц.
Правильная кластеризация поможет вам прилично сэкономить и существенно облегчит попадение в заветный ТОП.
Что вы думаете по этому поводу? А как вы делаете кластеризацию запросов семантического ядра?



{kind=link}
{kind=link}
Хорошая статья!
Использовал и использую для этих целей:
1. Кей Коллектор (когда небольшой проект)
2. Rush-analytics
3. SEmparser
4. Rank Tracker
Все хороши по своему, но предпочитаю №3 и №2
Semparser по качеству кластеризации устраивает?
“удлинитель на катушке 40м” не вошел почему-то в кластер с “удлинитель на катушке”
Потому что для него создался отдельный кластер. Вообще для запросов с популярными запросами есть смысл создавать отдельные посадочные страницы.
Правильно ли я понял, что сгенерированные ключевые слова ты не парсил, а просто снял частотность?
Хороший вопрос. Петя, ответь плиз, если еще не уехал))
Все, уезжаю 🙂
Да, так и есть. Потому что у меня были сгенерированы необходимые хвосты.
Полезно) Спасибо
Заходи ещё 😉
Я к сожалению никак не делаю кластеризацию 🙁 Спасибо за материал, будем работать!
Оо, а как же ты сажаешь запросы на посадочные?)
Не знал такого способа кластеризации.
А почему бы не кластеризовать запросы в том же кейколлекторе, ведь там есть такая функция. Правда там кластеризация основывается только на словах входящих в запрос
В кей коллекторе – ручная кластеризация, на схожих запросах тяжело определить, какой запрос посадить на отдельную страницу, а какие объединить. Как раз в статье приведен сложный случай, когда тяжело сделать это дело вручную.
Петя, в КК же есть возможность кластеризовать запросы по выдаче Яндекса (где указываем количество пересечений URL для помещения запроса в кластер). Это разве не то же самое, что делает Rush Analytics? Или у Раша свой алгоритм?
Андрей, как ни странно, я не сталкивался с данным функционалом в КК, по ходу упустил 🙂 Спасибо, гляну.
Мегаиндекс делает кластеризацию автоматически. Если разобраться, то очень удобно а главное бесплатно.
Петр, вышла новая программа для кластеризации Keyassort, тоже на основе выдачи группирует и намного дешевле получается. Проверь эти ключи, сравни качество.
Спасибо за подсказку, попробую.
Елена, благодарю за подсказку. Посмотрел видео-руководство. Похоже достойная программа)))
Здравствуйте! Давно не заходил на ваш сайт. Столько вопросов. Решил не разбрасывать вопросы по всем статьям, лучше всё спрошу здесь, хотя вопросы и не по теме, извините.
1. Есть ли какая-то достойная замена Кей Коллектор? Я понимаю, что лучше уж заплатить и не париться, но… я легких путей не ищу.
2. Установил на сайт консультанта онлайн JivoSite. Люди заходят на сайт, им выскакивает автоматическое приветствие, они продолжают “путешествовать” по сайту, через несколько минут я сам предлагаю помощь и.. они убегают. Почему люди так боятся? Почему уходят? Ответили бы, что помощь не нужна или вообще бы не отвечали, но продолжили читать статью.
3. Забыл… Что хотел спросить, если вспомню, обязательно напишу.
Заранее благодарю за ответы)
День добрый.
1. Нет. Если только “Словоеб”, но он не силен настолько. Я обязательно рекомендую покупать Кей Коллектор всем.
2. Раздражают всякие всплывающие окна, наверное. Или еще что-то. Нужно копать глубже, что за аудитория, по каким ключам заходят и т.д.
3. Ок. 🙂
Благодарю за ответы)
Извините за наглость, но ещё один вопрос: можно ли как-то сделать, чтобы на главной выводились полностью статьи (я проставил “читать далее”), а не одно предложение как у меня сейчас? Возможно что-то исправить в коде или с помощью плагина?
Да, конечно можно. В functions нужно указать длину слов/символов до обрывания текста. Тут лучше загуглить.
Извините может быть за столь непрофессиональный вопрос. так, как я еще дилетант. Приведу условный пример: допустим, сгенерировал и скластерилизовал я эти 43 запроса. В моем интернет-магазине, описание товара занимает примерно 1000 символов. Какое количество ключей будет допустимо? И что делать с остальными ключами, которые имеют близкое отношение к этому же товару? Создавать вторую посадочную страницу? и так далее? пока не закончатся ключи? Ответьте пожалуйста.
По поводу количества символов – нужно делать анализ конкурентов, посмотреть средние значения внутри ТОП-10. И на основе этих цифр можно сделать примерное предположение, сколько знаков контента нужно вам.
Если очень близкое, то можно отнести к существующему кластеру, если нет, то да, отдельную посадочную создавать.
Спасибо Пётр! Четко и ясно дали объяснение! Процветание вашему блогу!
Добрый день, есть вопросик, допустим 6 ключевых враз попало кластер и их нужно разместить на 1 урл, что делать с этими фразами? разместить на странице в тексте или тайтле или просто все фразы или слова из ключевых фраз распределяешь по контенту?
Не обязательно каждую фразу употреблять в точном вхождении, можно разбавлять и т.д. А для самых высокочастотных конечно – title, description, h1 и т.д.
Использовал: СпайВордс, XMind, КейКоллектор, с свои наработки в ексель
Добрый день, есть вопросик, допустим 6 ключевых враз попало кластер и их нужно разместить на 1 урл, что делать с этими фразами? разместить на странице в тексте или тайтле или просто все фразы или слова из ключевых фраз распределяешь по контенту?
Добрый день, Петр.
Спасибо за статью, есть 2 вопроса к вам:
1. Что вы можете сказать про программу Keyassort?
2.нужно ли использовать названия брендов на кириллице в текстах, тайтлах, заголовках?
это реально нужно?
Добрый день.
1. Не работал с ней.
2. Как правило, если вбить название бренда на кириллице, а в ТОПе сайты без обязательного присутствия кириллицы в Тайтле, то необязательно. То есть все на основе конкурентов.
Кластеризовал ядро в Rush Analytics для информационного сайта.
Но по любому надо делать доработку самому – это сервис и не до об этом забывать.
Хорошая статья!
Спасибо за подробную инструкцию. При вызове окна сбор с Ynadex.Direct не активна кнопка Получить данные
а я ожидал рассказа как кластеризовать в кей коллекторе. Смысл мне использовать сторонние платные сервисы если я потратился на КК?
А можно сделать кластеризацию в Коллекторе? Она там адекватная?
Сделать можно. Но вот на сколько она адекватная… Может Петя ответит.
помогите написать реферат на тему Логика кластеризации (программирование
Петь, а почему КК в автоматическом режиме не используешь для кластеризации?